
第一章 虚拟DOM和diff算法
1. 虚拟DOM
1.1 虚拟DOM概要
在传统页面的开发模式中,每次需要更新页面时都需要手动操作DOM来进行更新,频繁操作DOM造成浏览器性能消耗过大。
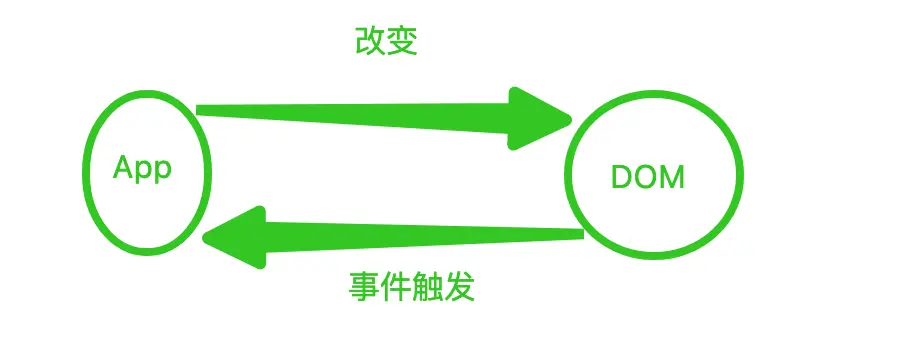

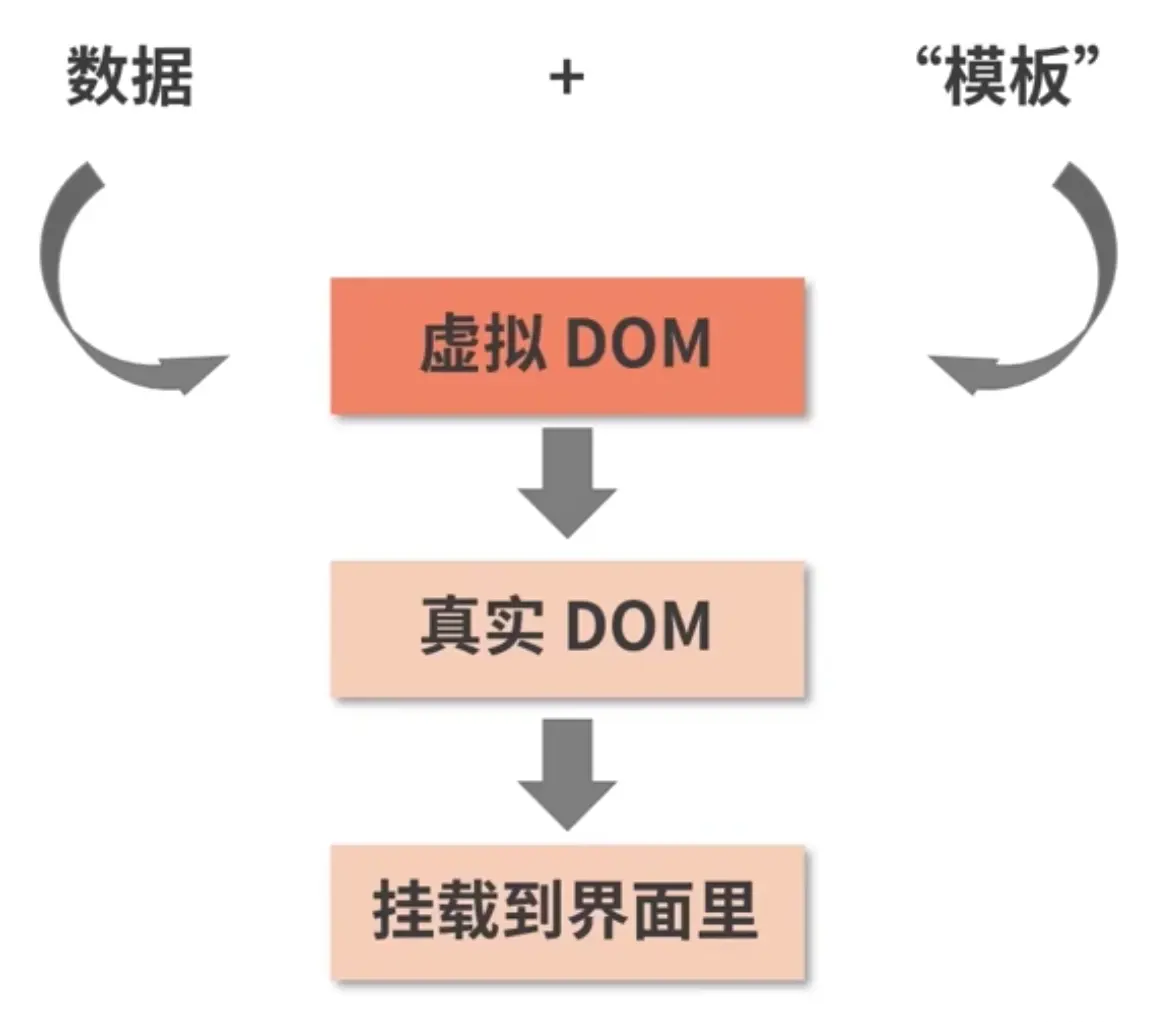
React把真实DOM树转换为JavaScript对象树,即Virtual DOM。Virtual DOM是一种编程概念,通俗点理解,虚拟DOM是一棵虚拟的JavaScript对象树,指的是它把真实的网页文档节点,虚拟成一个个的js对象,并以树型结构,保存在内存中。
Virtual DOM实际上是在浏览器端用javaScript实现的一套DOM API,包括所有Virtual DOM标签、生命周期的维护和管理、diff算法、更新的Patch方法,即上文中说到的fiber架构。
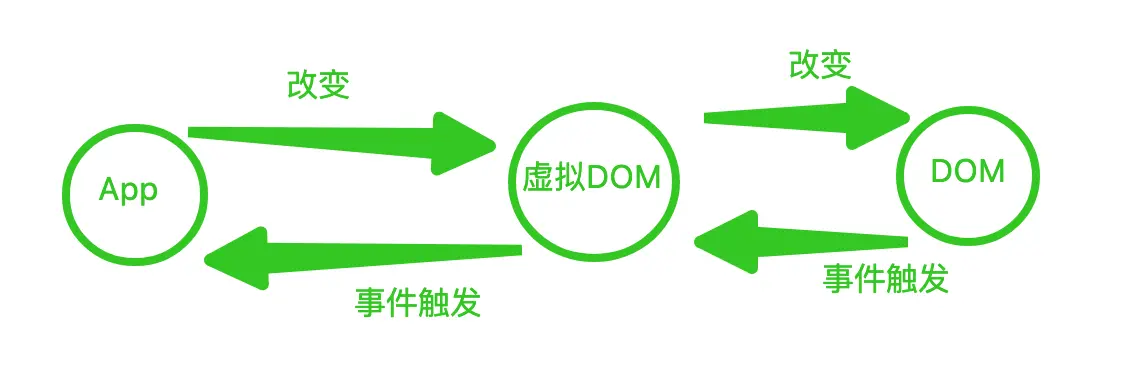
虚拟DOM本质上是JS和DOM之间的一个映射缓存,形态上为一个对象,可以描述了DOM元素和属性信息。虚拟DOM又称为核心算法的基石。
- 挂载阶段
React会结合JSX的描述构建出虚拟DOM树,然后通过ReactDOM.render实现虚拟DOM到真实DOM的映射。
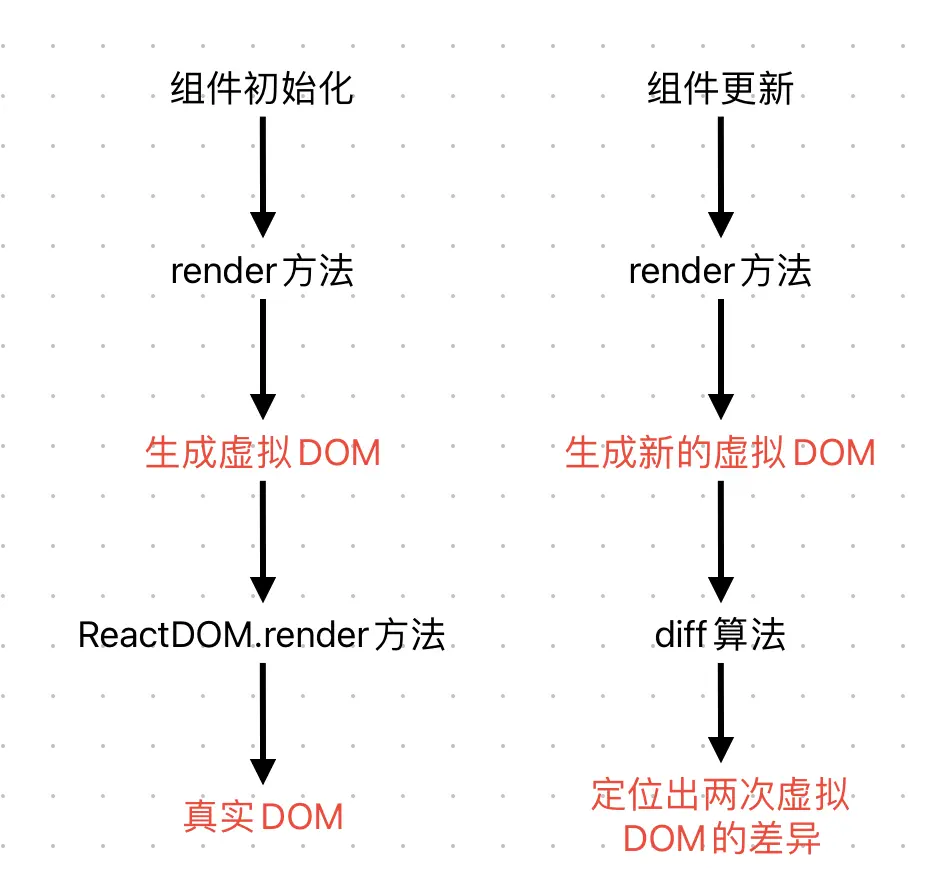
- 更新阶段
每次数据更新后,重新计算Virtual DOM,并和上一次生成的Virtual DOM做对比,对发生变化的部分做批量更新。React也提供了直观的shouldComponentUpdate生命周期回调,来减少数据变化后不必要的Virtual DOM对比过程,以保证性能。
通过JS模拟网页文档节点,生成JS对象树(虚拟DOM),然后再进一步生成真实的DOM树,再绘制到屏幕。如果有内容发生改变,React会重新生成一棵新的虚拟DOM树,与前面的虚拟DOM树进行比对diff,把差异的部分打包成patch,再应用到真实DOM中,然后渲染到浏览器屏幕上。
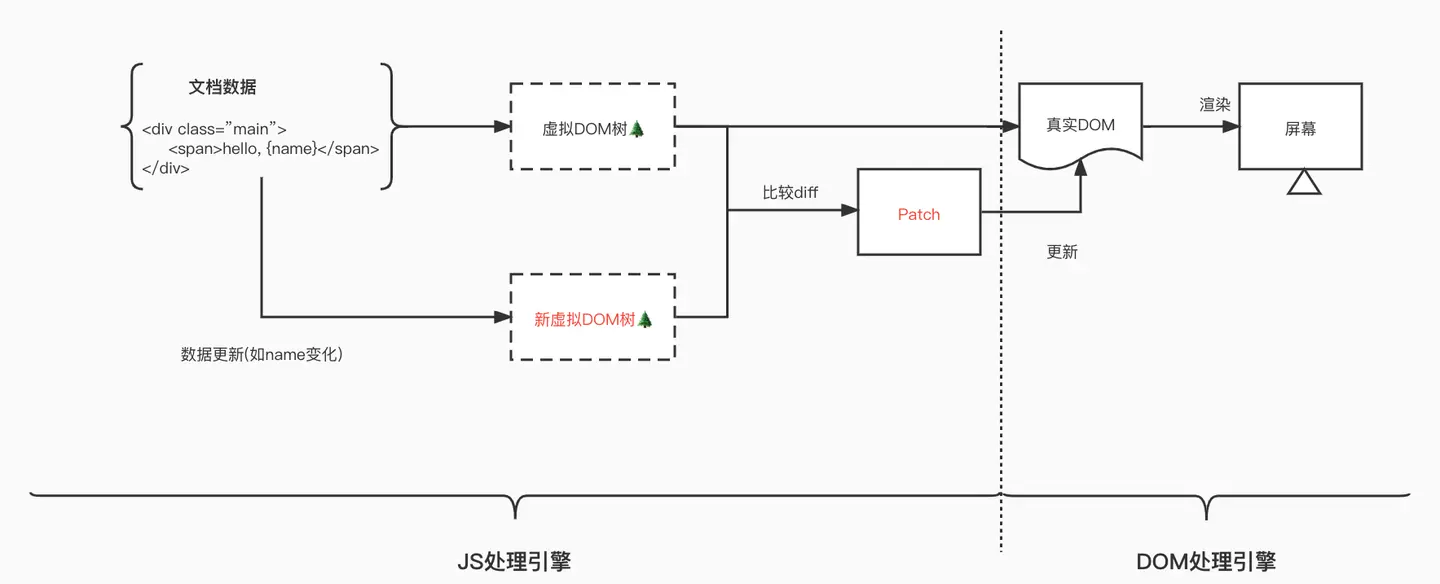

💡:虚拟DOM的劣势在于diff计算的耗时,但是DOM操作的能耗和JS计算的能耗不在一个量级
⚠️:虚拟DOM的优势不在性能,而在别处
1.2 虚拟DOM价值体现
- 研发体验和研发效率:开发者无需在手动操作原生DOM,即可实现数据驱动视图的更新
- 跨平台问题:将真实DOM转化为一套虚拟DOM,即可支持不同终端,降低成本
- 批量更新:虚拟DOM通过batch函数实现批量的更新。batch函数的作用是缓存每次生成的补丁集,并暂存在队列中,并在最后一次性完成所有更新
1.3 组件化
组件化:工程化思想在框架中的实现。每个组件可以是封闭的,也可以是开放的。
- “封闭”针对渲染工作流而言,在组件渲染工作流中,每个组件只处理它自身的渲染逻辑
- “开放”针对组件通信而言,React允许开发者基于“单向数据流”的原则完成组件间通信,而组件间通信又将改变通信双方/某一方内部的数据,进而对渲染结果产生影响
React是函数式组件思想,在发生数据(setState)更改后,会重新生成新的虚拟dom树,然后进行新旧虚拟dom树的diff对比(自上向下的全量diff)
Vue是组件响应思想,采用代理监听(watcher)数据,当一个组件内数据更改,可以明确知道并响应这个组件进行diff比较(局部订阅)
2. 调和与diff
2.1 调和
虚拟DOM是一种编程概念,在这个概念里,UI以一种理想化的或者虚拟的形式存在于内存中,并通过ReactDOM等类库使之与真实DOM同步,这一同步过程叫做“调和”。
“调和”又译为“协调”,指的是将虚拟 DOM映射到真实 DOM 的过程。因此严格来说,调和过程并不能和 Diff 画等号,调和是“使一致”的过程,而 Diff 是“找不同”的过程,它只是“使一致”过程中的一个环节。
调和器所做的工作是一系列的包括组件的挂载、卸载、更新等过程,其中更新过程涉及对 Diff 算法的调用。 由于Diff 是调和过程中最具代表性的一环:根据 Diff 实现形式的不同,调和过程被划分为了以 React 15 为代表的“栈调和”以及 React 16 以来的“Fiber 调和”。
React 16 的“Fiber 调和”指的是老的fiber和新的Element之前的diff。
2.2 diff算法
- diff策略的设计思想
传统diff:找出两个树结构之间的不同,需要进行遍历递归对树节点之间进行一一对比,时间复杂度为O(n^3)。
改良diff:在原有思想的前提下,提出了三个新的原则
- 跨层级的节点操作忽略不计
- 若两个组件属于同一类型,它们将拥有相同的DOM树型结构
- 处于同一层级的一组子节点,可以设置key作为唯一标识符,从而维持各个节点在不同渲染过程中的稳定性
- diff策略的逻辑
- diff算法性能突破的关键点在于“分层对比”
- 类型一致的节点才有进行diff的必要
- key属性的设置,可以帮助重用同一层级内的节点
官方对key属性的定义如下:key是帮助React识别哪些内容被更改、添加或者删除。key需要写在用数组渲染出来的元素内部,并且需要赋予其一个稳定的值。稳定在这里很重要,因为如果key值发生了变更,React会触发UI的重渲染。所以这是一个非常有用的特性。
const todoItem = todos.map(item =>{
return <div key={item.id}>{item.text}</div>
})
- tree diff
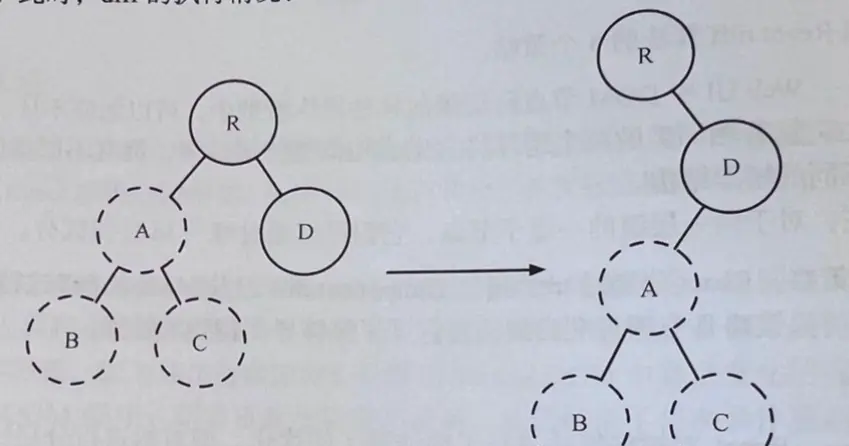
方式:分层比较,两棵树只会在同一层的节点进行比较
React通过updateDepth对虚拟DOM树进行层级控制,只会对相同层级的DOM节点进行比较,即同一个父节点下的所有子节点。当发现节点已经不存在时,该节点及其所有子节点会被完全删除,不会用于进一步的比较。从而实现一次遍历,便能完成整棵DOM树的比较。
跨节点移动并不是执行一个移动操作,而是执行创建、删除的操作,会以被移动节点为根节点的整棵树的重新创建,及其损耗性能。
当R发现A小时了,则会销毁A;当D发现多了一个节点A,会创建A及其子节点B、C。此时,diff 的执行情况为creat A -> creat B -> creat C -> delete A
- component diff
- 不同类型组件:直接删除和创建组件下的所有子节点
- 相同类型组件:对于同一类型的组件,有可能虚拟DOM并没有改变,继续比较反而浪费CPU和时间,React允许在shouldComponentUpdate()中判断该组件是否需要进行diff算法分析,或者通过 useMemo、useCallback、memo缓存结果
- element diff
当节点处于同一层级时,diff提供了三种节点操作,分别是插入、移动和删除,可以通过唯一标识符key进行判断和操作。
插入:新的组件类型不在旧集合里,是一个全新的节点,需要对新节点执行插入操作。
移动:旧集合里有新组件类型,且element是可更新的类型,通过移动操作实现DOM节点复用。
删除:旧组件类型不在新集合中,或者虽然在新集合中存在,但element不能直接复用和更新,需要删除DOM节点。
React首先对新集合进行遍历for( name in nextChildren),通过唯一key值判断新旧集合中是否存在相同的节点if (preChild === nextChild ),如果不存在则创建节点,如果存在则进行移动操作,移动前会判断下标if(child_mountIndex < lastIndex)。节点的操作过程中会不断的更新lastIndex,lastIndex记录已更新的当前节点的下标
React完成新集合中所有节点的差异化对比后,还需要对旧集合进行遍历,删除新集合中没有的旧节点。

2.3 Patch
React通过 patch 将 diff 计算出来的DOM差异队列更新到真实DOM节点上,最终让浏览器渲染出更新的数据。
patch会遍历差异队列,进行更新操作,包括新节点的插入、已有节点的移动和删除。
- diff算法分析阶段,添加差异节点到差异队列时是有序添加,所以patch时直接按照index操作真实DOM
- React完成所有差异计算,并全部放入差异队列后,才开始执行patch方法,完成真实DOM的更新
processUpdate:function(parentNode,updates){
for(var k = 0; k < updates.length;k++){
var update = updates[k];
switch(update.type){
// 插入
case ReactMultiChildUpdateTypes.INSERT_MARKUP:
// 移动
case ReactMultiChildUpdateTypes.MOVE_EXISTING:
// 删除
case ReactMultiChildUpdateTypes.REMOVE_NODE:
}
}
}
2.3 调和和diff区别
- 调和:使虚拟DOM和真实DOM一致
- diff:在新旧虚拟DOM中找不同
调和分为Core、Render、Reconciler三部分,其中Reconciler(调和器)所做的工作在组件挂载、卸载、更新等过程中,而diff可以看作是调和过程中最具代表性的一环。
第二章 React更新模式
1. legacy模式
legacy模式认为任务的优先级相同,而且只要开始更新,中途无法中断,如果有大量任务需要执行,则会延缓浏览器渲染,导致用户感知卡顿。
legacy模式如果需要采用不批量更新的方式,可以尝试将同步任务转为异步处理,但是浏览器性能会受影响。
const handleClick = ()=>{
setName(name+'lily');
setCount(count+1);
}
useEffect(()=>{
console.log('更新render'); // 只打印一次
})
const handleClick = ()=>{
setTimeout(()=>{
setName(name+'lily');
setCount(count+1);
})
}
useEffect(()=>{
console.log('更新render'); // 打印两次
})
2. concurrent并发模式
把更新任务划分优先级,更新开始后可以随时中断,从而执行更紧迫的任务,中断还可以恢复,总结来说,就是一个渲染过程可能被执行多次。
传统模式的异步任务没有批量更新,何尝不是一个性能漏洞。所以在concurrent并发模式下对这种情况做了优化,新模式的state更新叫做自动批量处理,采用异步任务统一开启更新调度。不再依赖事件系统,实现在异步条件下也可以实现批量更新。
const handleClick = ()=>{
setTimeout(()=>{
setName(name+'lily');
setCount(count+1);
})
}
useEffect(()=>{
console.log('更新render'); // 打印一次
})
3. 更新流程
3.1 scheduleUpdateOnFiber 更新入口
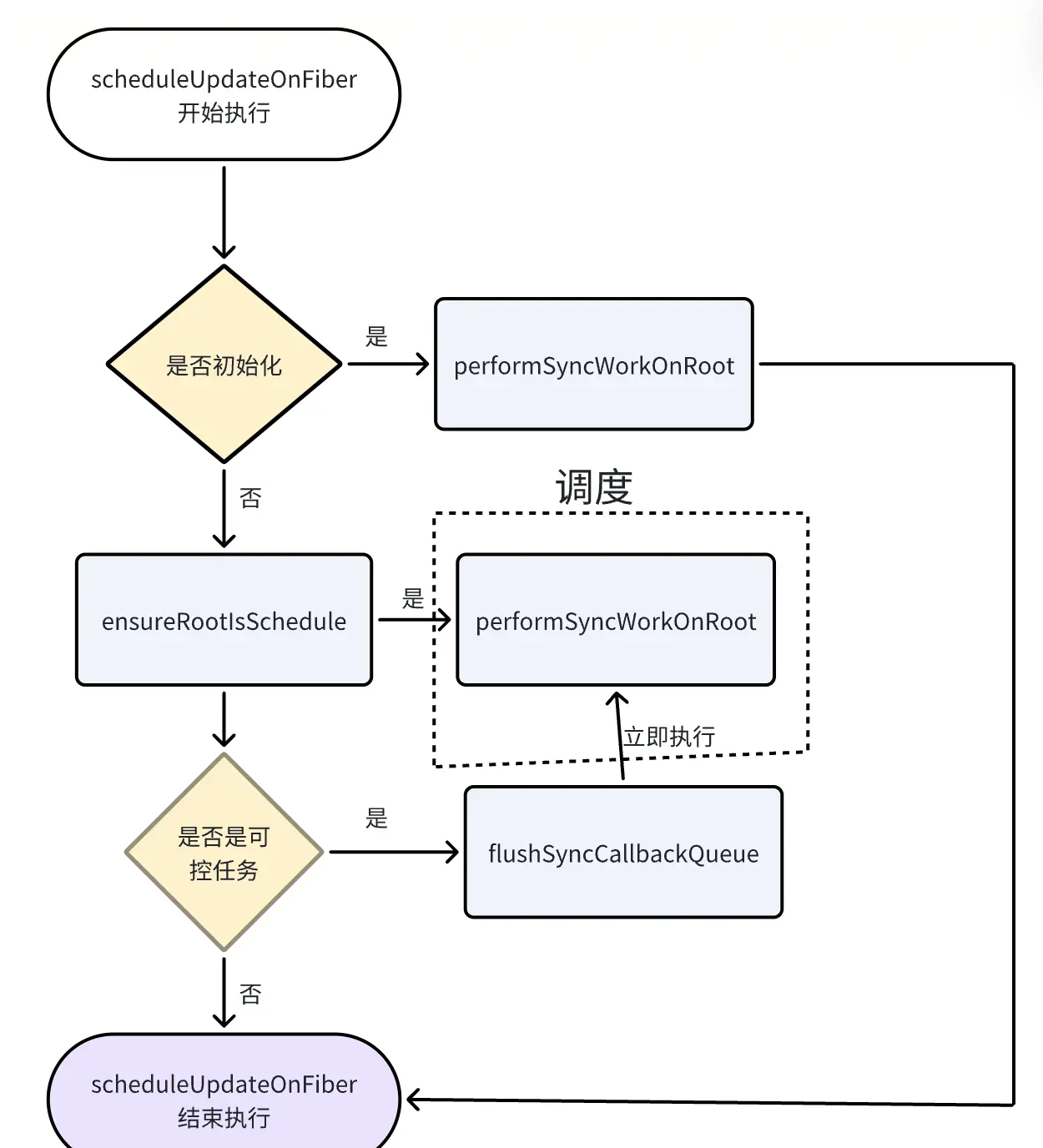
在React中无论是初始化还是更新state,内部调用的都是scheduleUpdateOnFiber方法。scheduleUpdateOnFiber可以看做是整个React应用的入口。
1.内部主要做的事情
- 通过当前的更新优先级lane,将当前fiber到Rootfiber的父级链表上的所有优先级更新
- 在非批量更新状态下,直接执行更新任务
- useState和setState任务会进入ensureRootIsSchedule调度流程
- 当前执行的任务类型为NoContext时,会调用flushSyncCallbackQueue执行任务队列中的任务
可控任务:React事件系统事件、addEventListenter监听事件
非可控任务:延时器(Timer)、微任务队列(Microtask)
- 主要函数
markUpdateLaneFromFiberToRoot:向上调和更新优先级
performSyncWorkOnRoot:直接进入调和阶段更新fiber树状态
ensureRootIsSchedule:进入调度流程
flushSyncCallbackQueue:执行任务队列里面的任务
3.2 渲染阶段、commit阶段
flushSyncCallbackQueue执行完任务后,会进入渲染和commit阶段。
渲染阶段:执行类组件的渲染函数或执行函数组件本身,得到新的react element,diff比较差异,处理每一个待更新的fiber节点并打上flags
commit阶段:处理带有flags的fiber,patch操作真实DOM节点,执行生命周期等。Commit阶段包括before mutation、mutation和layout,DOM元素的更新发生在mutation阶段
3.3 调度任务实现
React底层的批量更新可以用一句话概括:多次触发的更新,只有第一次会进入调度中。
// 同步任务
const handleclick = ()=>{
setNum(num + 1);
setNum(num + 1);
}
// 异步任务
const handleClick = ()=>{
setTimeout(()=>{
setNum(num + 1);
setNum(num + 1);
})
}
😊同步任务执行流程:
1)事件上下文:开启事件开关 –> 进入第一次setNum
第一次setNum上下文:scheduleUpdateOnFiber –> ensureRootIsSchedule –> 放入回调函数performSyncWorkOnRoot到任务队列
2)进入第二次setNum
第二次setNum上下文:scheduleUpdateOnFiber –> ensureRootIsSchedule –> 退出
3)事件上下文:开启事件开关 –> flushSyncCallbackQueue
flushSyncCallbackQueue –> 执行回调函数 performSyncWorkOnRoot –> 调和阶段 –> renderRoot –> commitRoot –> 浏览器绘制
🐯异步任务:
1)事件上下文:开启事件开关 –> 关闭事件开关 –> flushSyncCallbackQueue(任务队列为空)
2)setTimeout上下文:执行第一次setNum
第一次setNum上下文:scheduleUpdateOnFiber –> ensureRootIsSchedule –> 放入回调函数performSyncWorkOnRoot到任务队列 –> flushSyncCallbackQueue –> 执行回调函数 performSyncWorkOnRoot –> 调和阶段 –> renderRoot –> commitRoot
3)回到setTimeout上下文:执行第二次setNum
第二次setNum上下文:scheduleUpdateOnFiber –> ensureRootIsSchedule –> 放入回调函数performSyncWorkOnRoot到任务队列 –> flushSyncCallbackQueue –> 执行回调函数 performSyncWorkOnRoot –> 调和阶段 –> renderRoot –> commitRoot
4)JS执行完毕:浏览器绘制
4. 并发模式调整优先级
- 开启concurrent并发模式
首先需要开启React 18版本的并发模式,才能使用相关优化
const container = document.getElementById("root");
const root = createRoot(container);
root.render(
<Provider store={store}>
<Router />,
</Provider>
);
- flushSync提高优先级
将回调函数中的state更新任务放在一个较高优先级的更新中,flushSync在同步条件下,会合并之前的任务。
const handleClick = ()=>{
setTimeout(()=>{
setNumber(1);
})
setNumber(2);
ReactDOM.flushSync(()=>{
setNumber(3);
})
setNumber(4);
}
console.log(number); // 3 4 1
- useTransition降低优先级
通过startTransition把不是特别迫切的任务隔离开来,降低任务优先级。
底层实现类似于useState + startTransition。
import React, { useState, useTransition } from "react";
const List=()=>{
const [count, setCount] = useState(0);
const [isPending, startTransition] = useTransition();
function handleClick() {
startTransition(() => {
setCount(count + 1);
});
}
return (
<>
<h1>{count}</h1>
<div onClick={handleClick} style={{color: isPending ? 'red' : 'black'}}>
+1
</div>
</>
);
}
export default List; // 点击按钮过程中会数据更新前会有字体变为红色的效果
startTransition与传统方式对比:
- startTransition:同步执行、且早于setTimeout、不会减少渲染次数、可以中断执行、不会造成页面卡顿
- setTimeout:异步执行、会减少渲染次数、不可中断、和合成事件一样同为宏任务,所以会造成页面卡顿
- 防抖/节流:其本质依然是setTimeout执行,只是通过减少了执行频率来减少渲染次数
- useDeferredValue获取延迟状态
startTransition是把内部任务变成过度任务,而useDeferredValue是把原值通过过度任务得到新的值,这个值作为延时状态。
底层实现类似于useState + useEffect+ startTransition。
import React, { useDeferredValue, useState } from "react";
const List=()=>{
const [count, setCount] = useState(0);
const deferredCount = useDeferredValue(count);
function handleClick() {
setTimeout(()=>{
setCount(count + 1);
},1000)
}
return (
<>
<h1>{deferredCount}</h1>
<button onClick={handleClick}>+1</button>
</>
);
}
export default List;
- Suspense+React.lazy
Suspense组件的fallback属性,用来代替Suspense处于loading状态时的渲染内容。
React.lazy通过import()动态加载组件,返回值为promise对象。
渲染流程:React.lazy通过throw返回Promise对象,Suspense接收Promise对象,通过.then获取resolve状态中的组件,并渲染该组件。
const App = React.lazy(() => import("./App"));
const List = React.lazy(() => import("./List/List"));
const CaseTest = React.lazy(()=> import("./CaseTest/CaseTest"));
export default () => (
<Suspense>
<BrowserRouter>
<Routes>
<Route path="/" element={<App />} />
<Route path="/list" element={<List />} />
<Route path="/test" element={<CaseTest/>}/>
</Routes>
</BrowserRouter>
</Suspense>
);
第三章 React架构设计
1. Stack Reconciler
- React官方设想
React官方认为,React是用JavaScript构建快速响应的大型Web应用程序的首选方式。
- 单线程的JS与多线程的浏览器
多线程的浏览器除了要处理JavaScript线程以外,还需要处理各种各样的任务线程,如处理DOM的UI渲染线程等。由于JavaScript线程也是可以操作DOM的,所以这两个线程在运行时是相互排斥的,即当其中一个线程执行时,另一个线程只能挂起等待。
如果JS线程执行长任务,则会导致渲染线程一直处于等待状态,界面就会长时间得不到更新,带给用户的体验就是所谓的“卡顿”。
- 页面卡顿的原因

React15的栈调和机制下的diff算法其实是树深度优先遍历的过程。Reconciler调和器会重复“父组件调用子组件”的过程直到最深的一层节点更新完毕,才慢慢向上返回。
Stack Reconciler过程的致命性问题在于其是同步的,不可以被打断,所以需要的调和时间会很长,导致JavaScript线程长时间地霸占主线程,进而导致上文中所描述的渲染卡顿/卡死、交互长时间无响应等问题。
2. React fiber
2.1 fiber概念
但是在React15及之前版本的Stack Reconciler在交互体验等方面显出疲态,大型页面卡顿问题明显。在React16.x 版本中将其最为核心的diff算法进行完全的重写,使其以“Fiber Reconciler”的全新面貌示人,从而向其快速响应目标更进一步。
React和Vue框架都是通过改变VDOM来实现真实DOM的更新,而fiber作为React中最小粒度的执行单元,所以可以将其理解成VDOM。
每一个Element类型都会有一个与之对应的fiber类型,当Element发生变化引起组件更新时,会通过fiber层面做一次调和和改变,形成新的DOM做视图渲染,所以可以将fiber理解为Element和真实DOM之间的交流枢纽站。
Fiber就是比线程还要纤细的一个过程,也就是所谓的“纤程”。纤程的出现意在对渲染过程实现更加精细的控制。
type Fiber = {
------- DOM实例 -----------
tag, // 标记不同的组件类型
type, // 组件类型
stateNode, // 实例对象
------- 构建Fiber树 -----------
return, // 指向父节点
child, // 指向子节点
sibling, // 指向第一个兄弟节点
alternate, // 当前Fiber在workInProgress中对应的Fiber
------- 状态数据 -------------
pendingProps, // 即将更新的props
memoizedProps, // 旧的props
memoizedState, // 旧的state
-------- 副作用 --------------
updateQueue, // 状态更新的队列
effectTag, // 将要执行的DOM操作
firstEffect, // 子树中第一个
lastEffect, // 子树中最后一个
nextEffect, // 链表中下一个
expirationTime, // 过期时间
mode, // 当前组件及子组件的渲染模式
}
2.2 fiber树
每一个fiber节点都包含三个重要的属性:return、child、sibling。
其中return指向父级fiber节点,child指向子级fiber节点,sibling指向兄弟fiber节点。
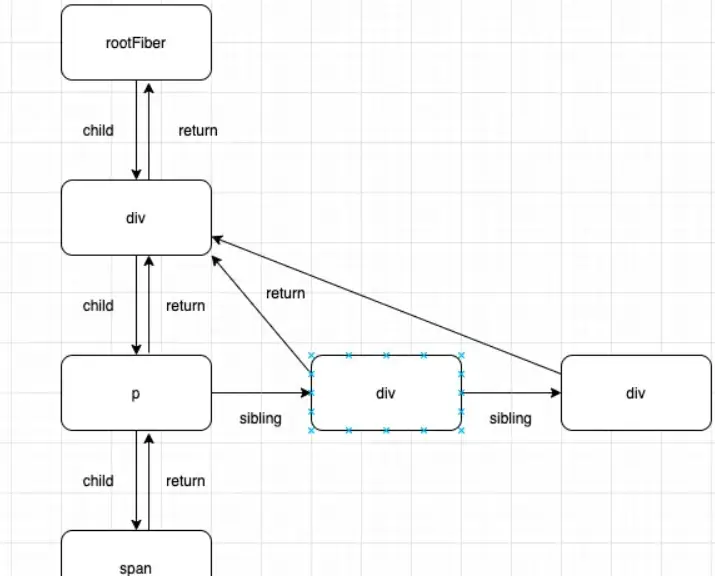
Fiber树的创建流程:
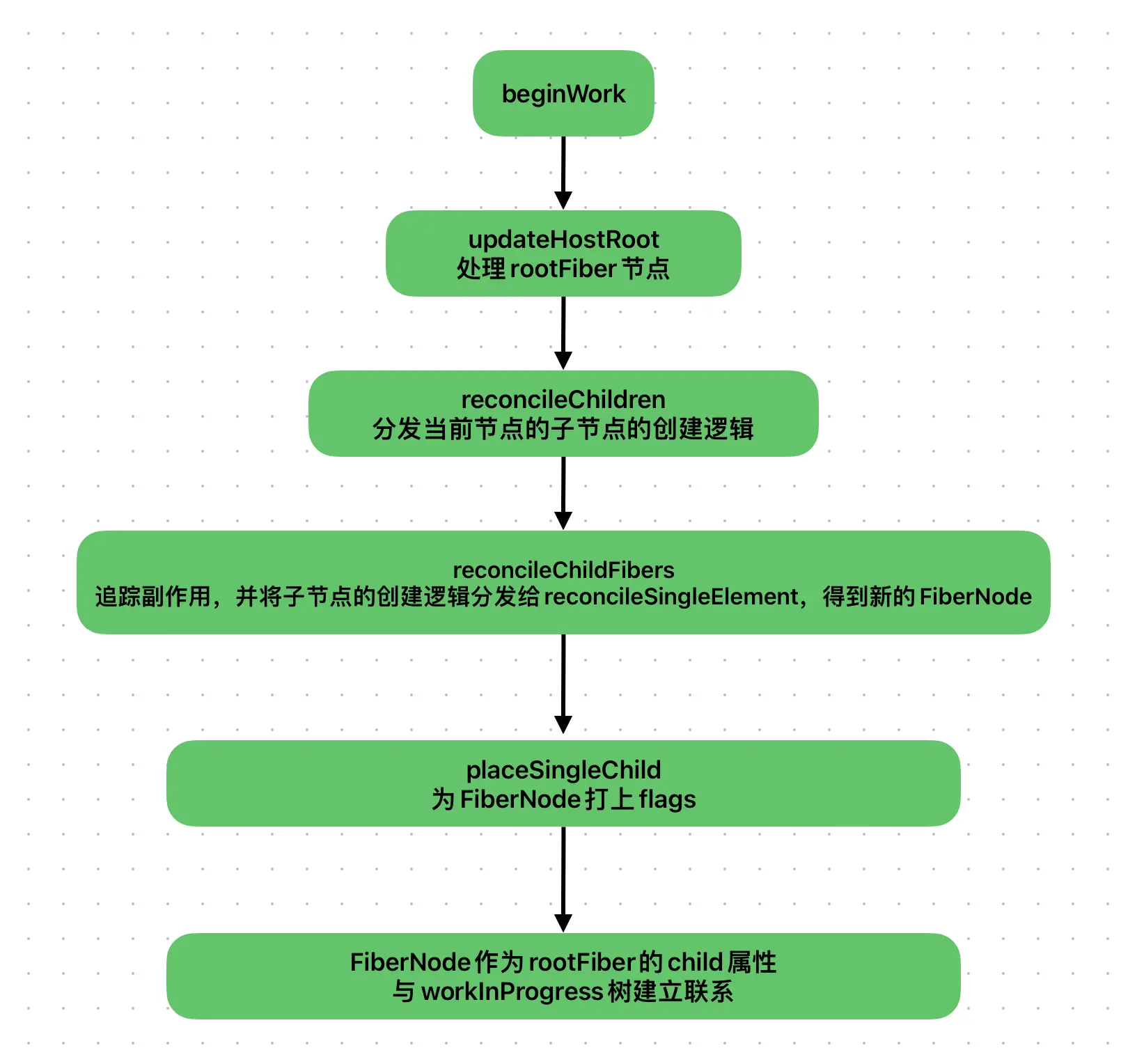
1)beginWork函数
第一步:循环创建新的Fiber节点
第二步:Fiber节点间创建联系
将通过child、return、sibling3个属性建立关系,其中child、return记录的是父子节点关系,sibling记录的则是兄弟节点关系。
2)completeWork函数
执行时机:当beginWork递归无法进行时,则会执行completeWork
特点:严格的自底向上执行
作用:处理Fiber节点到DOM节点的映射逻辑
核心工作内容:
- 创建DOM节点,并将创建好的DOM节点赋值给workInProgress节点的stateNode属性
- 通过appendAllChildren函数将DOM节点插入DOM树中(子Fiber节点对应的DOM节点挂载到父Fiber节点对应的DOM节点中)
- 为DOM节点设置属性
render阶段主要为了寻找新旧Fiber树的不同,而commit阶段则负责实现更新。
3)副作用链effectList
副作用链可以理解为render阶段“工作成果”的一个集合,每一个Fiber节点都维护了一个独有的effectList,effectList不只记录当前需要更新的节点,还记录了后代节点信息等。
把所有需要更新的Fiber节点单独串成一串链表,方便后续有针对性地对它们进行更新。这就是所谓的“收集副作用”的过程。
effectList的重要属性:
- firstEffect:链表的第一个Fiber节点
- lastEffect:链表的最后一个Fiber节点

2.3 Fiber渲染流程
- ReactDOM.render:同步渲染,又称为legacy模式(传统)
- ReactDOM.createRoot:异步渲染,又称为concurrent模式(并发执行)
- ReactDOM.render

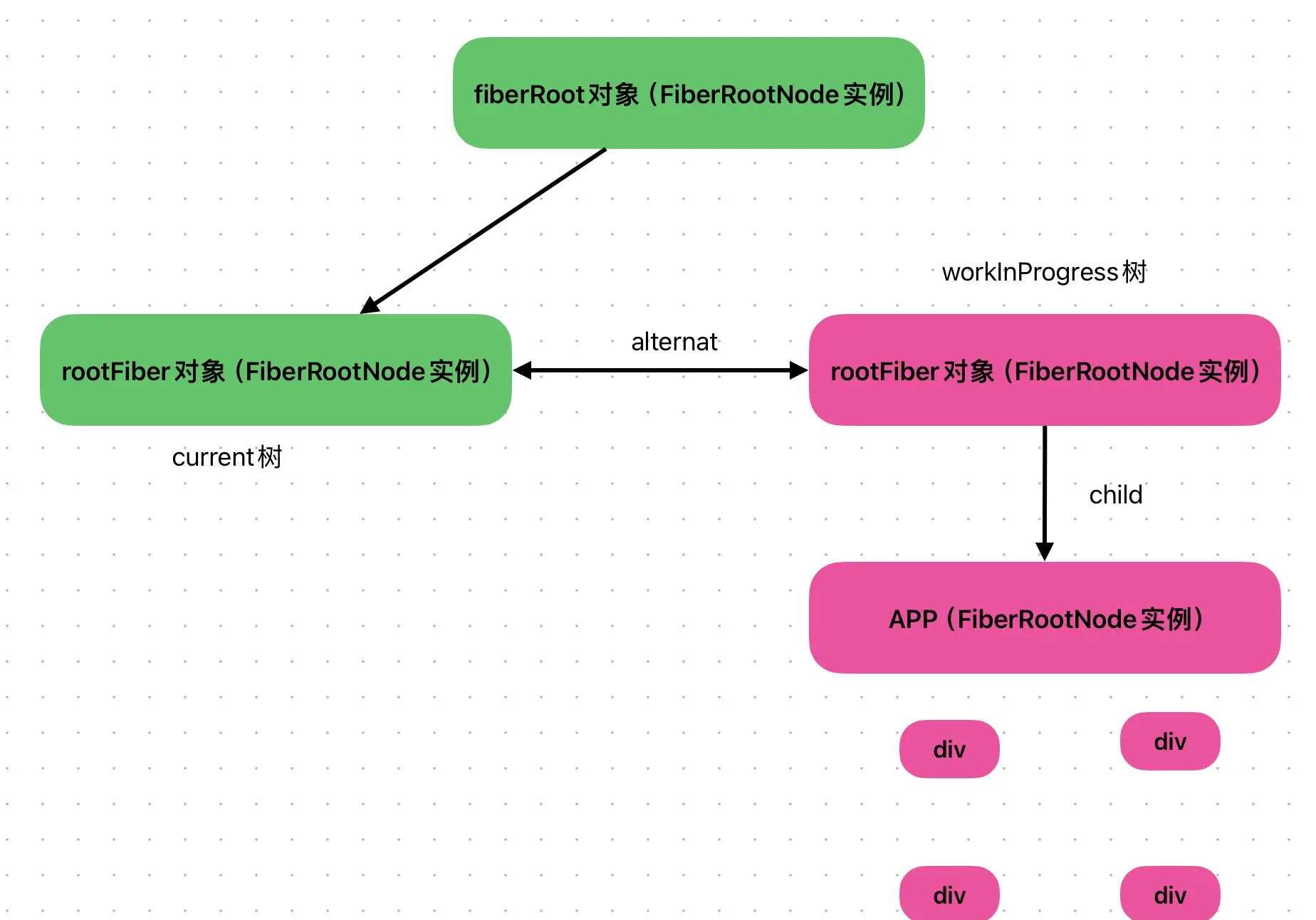
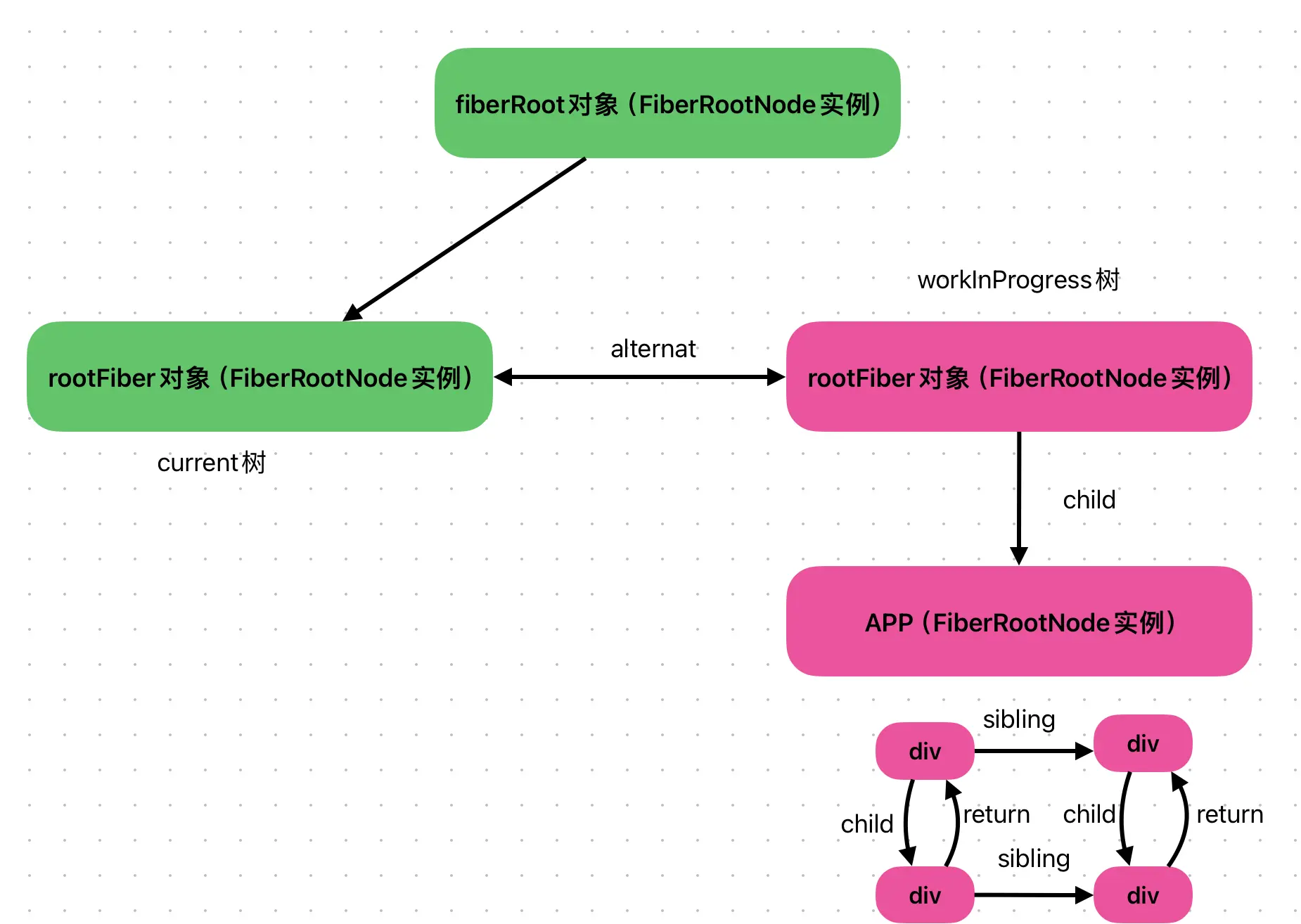
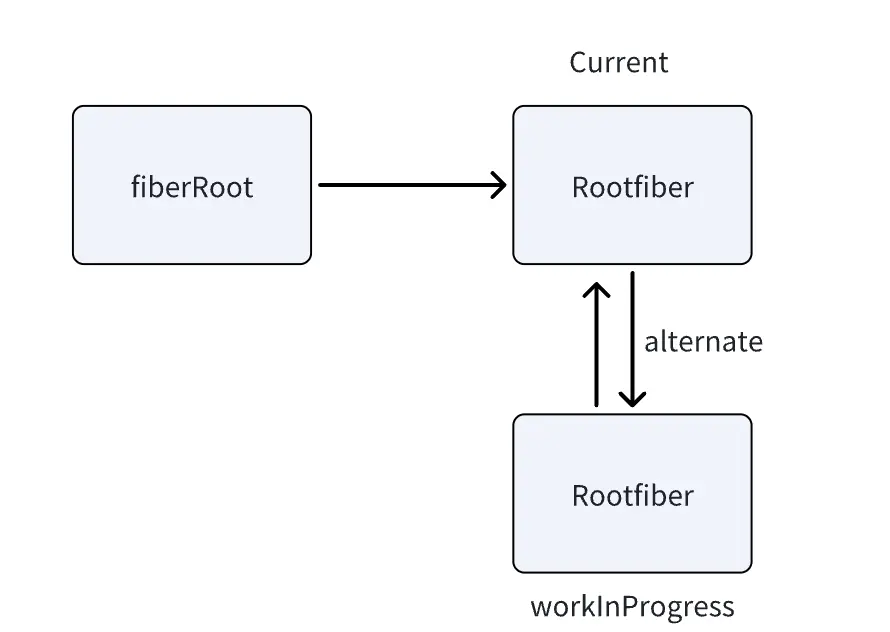
当通过ReactDOM.render创建应用时,底层会创建两个节点,分别是fiberRoot和Rootfiber
fiberRoot:应用的根节点,在首次构建时创建,全局唯一;
Rootfiber:ReactDOM.render渲染的组件对应的fiber节点,不唯一;
一个React应用可以有多个Rootfiber,但是只能有一个fiberRoot
如果有一个子节点,则直接构建fiber即可;如果有多个子节点,会先遍历Element对象,然后逐一创建fiber,每个子节点fiber的return指针指向父级fiber,同层子节点之间通过sibling建立联系,构建下一层级节点时,通过child指针关联。
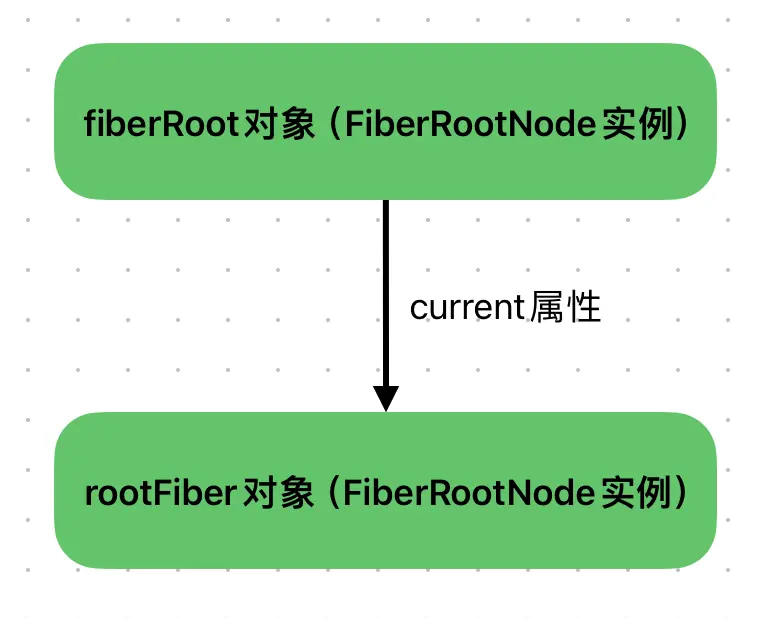
fiberRoot包含rootFiber:在fiberRoot对象中,有一个current属性存储rootFiber。
rootFiber指向fiberRoot:在rootFiber对象中有一个stateNode属性指向fiberRoot。
updateContainer方法的核心工作为:
第一步:请求当前Fiber节点的lane(优先级)
第二步:结合lane(优先级)创建当前Fiber节点的update对象,并将其入队列
第三步:调度当前节点(rootFiber)
performSyncWorkOnRoot是render阶段的起点,render阶段的任务就是完成 Fiber树的构建,它是整个渲染链路中最核心的一环。
- ReactDOM.createRoot
React底层会根据一个mode属性,决定工作流程是一气呵成(同步)还是分片执行(异步)。此处省略mode相关的源码,感兴趣的同学可以去官网查看。
2.4 render阶段
- React15栈调和
React15的调和过程是一个递归的过程,ReactDOM.render触发的同步模式下仍然是一个深度优先搜索的过程。
在这个过程中,beginWork将创建新的Fiber节点,completeWork则负责将Fiber节点映射为DOM节点。
- React16Fiber
首先会构建两棵树,一颗为workInProgress树,一颗为current树
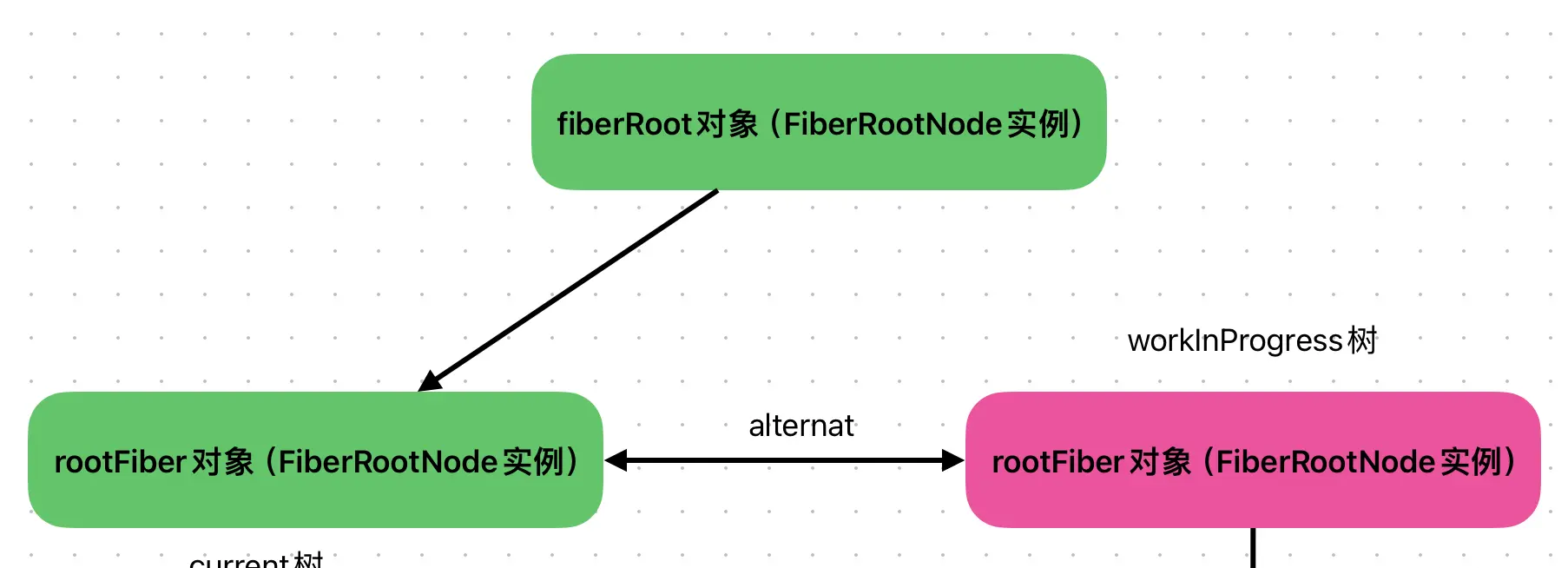
React双缓冲树原理:
React底层会同时构建两颗树:一颗workInProgress(在内存中创建),一颗为Current(渲染树),两颗树之间通过一个alternate指针相互指向。
当React项目初始化的时候,两棵树是相同的;当React项目更新时,所有的更新都发生在workInProgress上面,更新结束时,workInProgress的状态是最新的,它将变成Current树,用于渲染视图。
current树与worklnProgress树可以对标“双缓冲”模式下的两套缓冲数据,当current树呈现在用户眼前时,所有的更新都会由worklnProgress树来承接。workInProgress树将会在用户看不到的地方(内存里)悄悄地完成所有改变,直到current指针指向workInProgress树时,用户可以看到更新后的页面。
2.5 commit阶段
特点:决定的同步更新流程
- before mutation阶段:DOM节点还没有被染到界面上去
- mutation:负责DOM节点的渲染
- layout:处理DOM染完毕之后的收尾逻辑,以及把fiberRoot的current指针指向worklnProgress Fiber树
2.6 fiber解决的问题
React V15以及之前的版本中,对于VDOM采用的是递归遍历的方式进行更新,比如一次更新会从应用的根部开始递归,而且一旦开始,中间不能中断,如果项目很大,则会造成浏览器卡顿甚至更严重的性能问题。
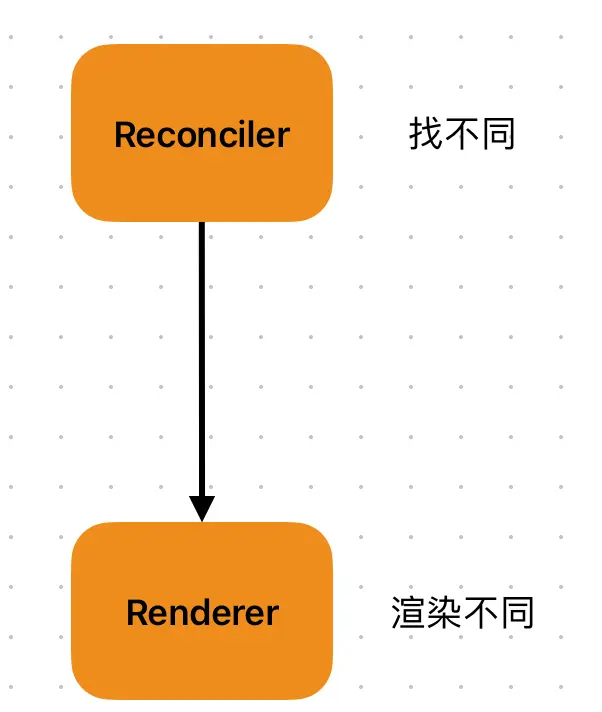
React V16引入的fiber架构,之所以能够解决卡顿问题,是因为其更新过程的Reconciler调和器的作用。在React中每一个fiber都可以作为一个执行单元来处理,更新时会判断fiber是否需要更新(V17之前通过expiration过期时间,V17之后通过lane架构),浏览器是否还有空间和时间来执行更新。如果判断结果是不更新,则是直接跳过;如果没有时间更新,就把主动权交给浏览器去执行渲染、绘制等任务。等到浏览器有空余时间,再通过scheduler(调度器)再次恢复渲染,从而提高用户体验。
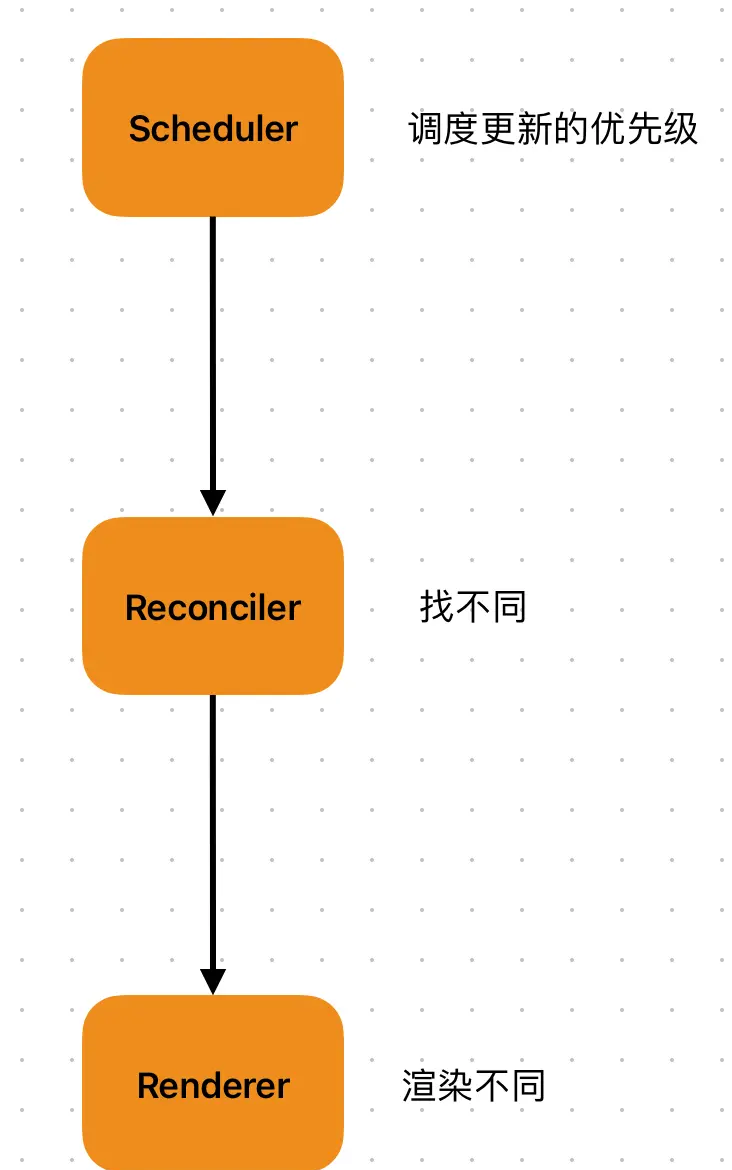
Scheduler:调度器,其工作流程大致如下:
每一个封信任务都会赋予一个优先级,当更新任务抵达调度器时,高优先级的任务会优先进入Reconciler层。(设置优先级)
此时如果有新的更新任务抵达调度器,调度器会比较其优先级,若发现B的优先级高于当前任务A,那么当前处于Reconciler层的A任务就会被中断。将更高优先级的B任务推入Reconciler层。当B任务执行完毕后,就会进入下一轮的任务调度。(可中断)
之前被中断的A任务会被重新推入Reconciler层,继续A任务的渲染流程。(可恢复)
2.7 fiber核心特点
- 增量渲染
React Fiber 将更新任务拆分成多个小任务单元(称为 “fiber”),并使用优先级调度器来处理这些任务,以提高响应性和用户体验
- 优先级调度
Fiber 引入了优先级概念,使 React 能够根据任务的优先级来决定任务的执行顺序,确保高优先级任务得到及时处理
- 中断与恢复
React Fiber 允许在渲染过程中中断任务,然后在适当的时机恢复执行,从而避免了阻塞的情况
React15的更新渲染流程:
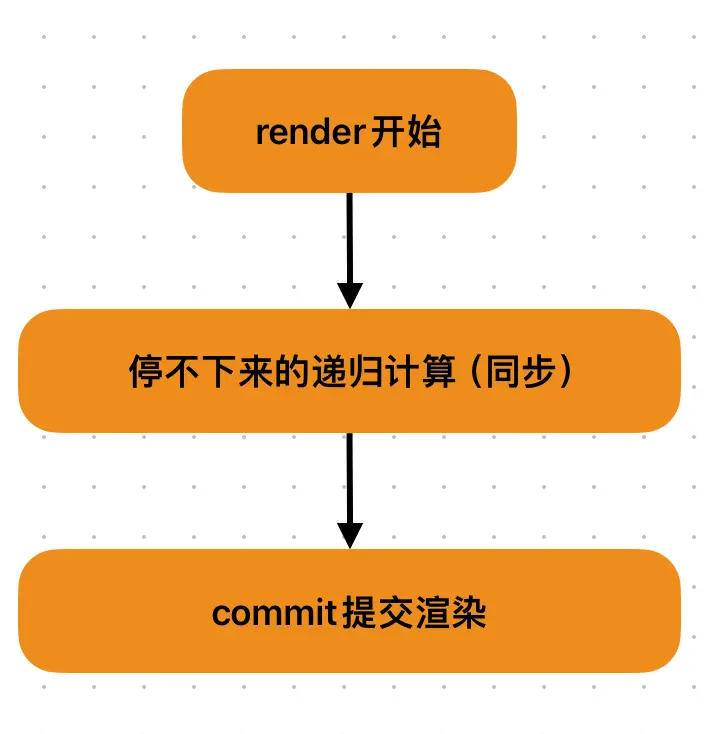
React16的更新渲染流程:
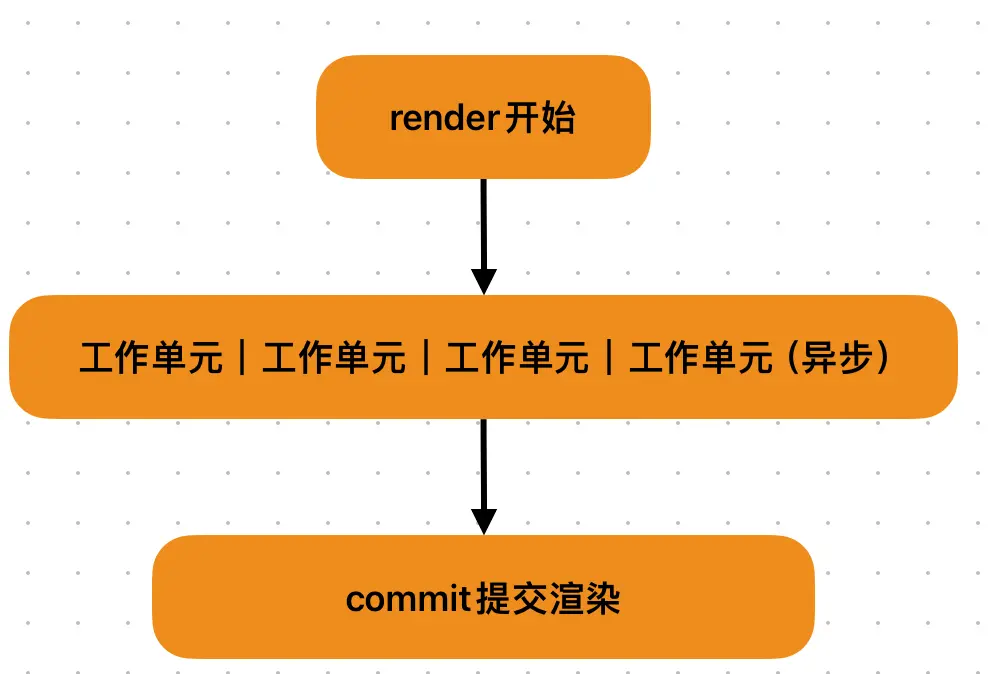
改进🚚:React在render阶段将一个庞大的更新任务,拆解为若干个小的更新工作单元,每一个单元都被设置了一个不同的优先级。React根据优先的高低,实现工作单元的打断和恢复等,从而完成整个更新任务。
⚠️:正因为Fiber有如上的更新,所以需要废除componentWillXXX的生命周期。
- 任务取消
Fiber 具备任务取消的能力,可以取消不必要的更新,提高性能
2. React 位运算
- 位运算概念
计算机存储数据时采用的是二进制方式,位运算就是对二进制位进行运算操作。
常用位运算包括:
- &:都为1,则返回1;
- |:都为0,则返回0;
- ^:只有一个1,才返回1
- ~:反转操作,0返回1,1返回0
- ‘<<:向左移动n比特位
- ‘>>’:向右移动n比特位
- React 位运算应用
更新优先级(位掩码):每一次更新时,会把待更新的fiber增加一个更新优先级,称为Lane。Lane的值越小其优先级越高。
更新上下文(位掩码):每一次更新时,会通过ExecutionContext判断现在的更新上下文。
function batchedEventUpdate(){
var prevExecutionContext = executionContext;
executionContext |= EventContext; // 赋值事件上下文
try{
return fn(a); // 执行函数
}finally{
executionContext = prevExecutionContext; // 重置之前的状态
}
}
React 事件系统中给ExecutionContext赋值EventContext,在执行完事件后,重置其值为之前状态。事件系统中的更新可以感知到目前的更新上下文是EventContext,会认为是可控任务,就可以实现批量更新。
更新标识(位掩码):每一次更新时,会把需要更新的fiber搭上更新标识flags,证明fiber是什么更新类型。
3. React数据更新结构
- 批量更新,减少更新次数
React通过更新上下文的方式,来判断每一次更新是在什么上下文环境下,比如在React事件系统中,就有ExecutionContext === EventContext,可以批量更新任务
- 更新调度,主动权交给浏览器
React Scheduler 是React处理更新的重要模块。在React中维护了一个更新队列,去保存待更新的任务,当地一次产生更新的时候,会把当前更新任务放入更新队列,然后执行更新,接下来调度器会向浏览器申请空闲时间,在此期间,如果有更新任务插入(微任务等),就会放入更新队列,等浏览器有空闲时间时在执行,每次执行完会再次申请空闲帧,一直到待更新队列中没有任务为止。这样改进的特点是交出了主动权,避免执行任务造成浏览器阻塞。
- 更新标识Lane、ExpirationTime
React 为了区分更新任务,每一次更新都会创建一个Update,并把Update赋予一个更新标识。其中ExpirationTime代表过期时间,如果过期则会立即执行,如果没有过期,就会去执行更高优先级的任务。Lane解决了ExpirationTime无法区分并发场景中的任务优先级,Lane采用的是位运算,一个Lane上可以有多个任务合并,可以准确描述出fiber节点存在的任务情况,还可以区分任务,从而处理并发场景下的任务优先级。
- 进入更新
当发生更新时,React会根据跟新标识找到更新源头,然后从Root开始向下调和,调和完成后会执行渲染和commit阶段。渲染阶段的核心就是diff对比,找到需要更新的差异队列,commit阶段负责执行DOM更新、生命周期和更新的回调函数。
4. React Scheduler核心
Fiber架构下的异步渲染(即Concurrent模式)的核心特征分别是“时间切片”与“优先级调度”。
4.1 时间切片
// legacy模式
function workLoopSync() {
// Already timed out, so perform work without
while(workInProgress!== null){
performUnitOfwork(workInProgress);
}
}
// concurrent模式
function workLoopConcurrent() {
// Perform work until Scheduler asks to yield
while(workInProgress !== null && !shouldYield()){
performUnitOfwork(workInProgress);
}
}
当shouldYield()调用返回为true时,则说明当前需要对主线程进行让出。此时 whille循环的判断条件整体为false,while循环将不再继续执行。
原理💡:React会根据浏览器的帧率计算时间切片的大小,并结合当前时间,计算出每一个切片的到期时间。在workLoopConcurrent函数中,每次执行都会判断当前切片是否到期,如果到期则让出主线程的使用权。

4.2 优先级调度
通过调用unstable_scheduleCallback发起调度,会结合任务的优先级信息为其执行不同的调度逻辑。
- startTime: 任务的开始时间
- expirationTime: expirationTime越小则任务的优先级就越高
- timerQueue: 一个以startTime为排序依据的小顶堆。它存储的是 startTime大于当前时间的任务(待执行任务)
- taskQueue: 一个以expirationTime为排序依据的小顶堆,它存储的是 startTime小于当前时间的任务(已过期任务)
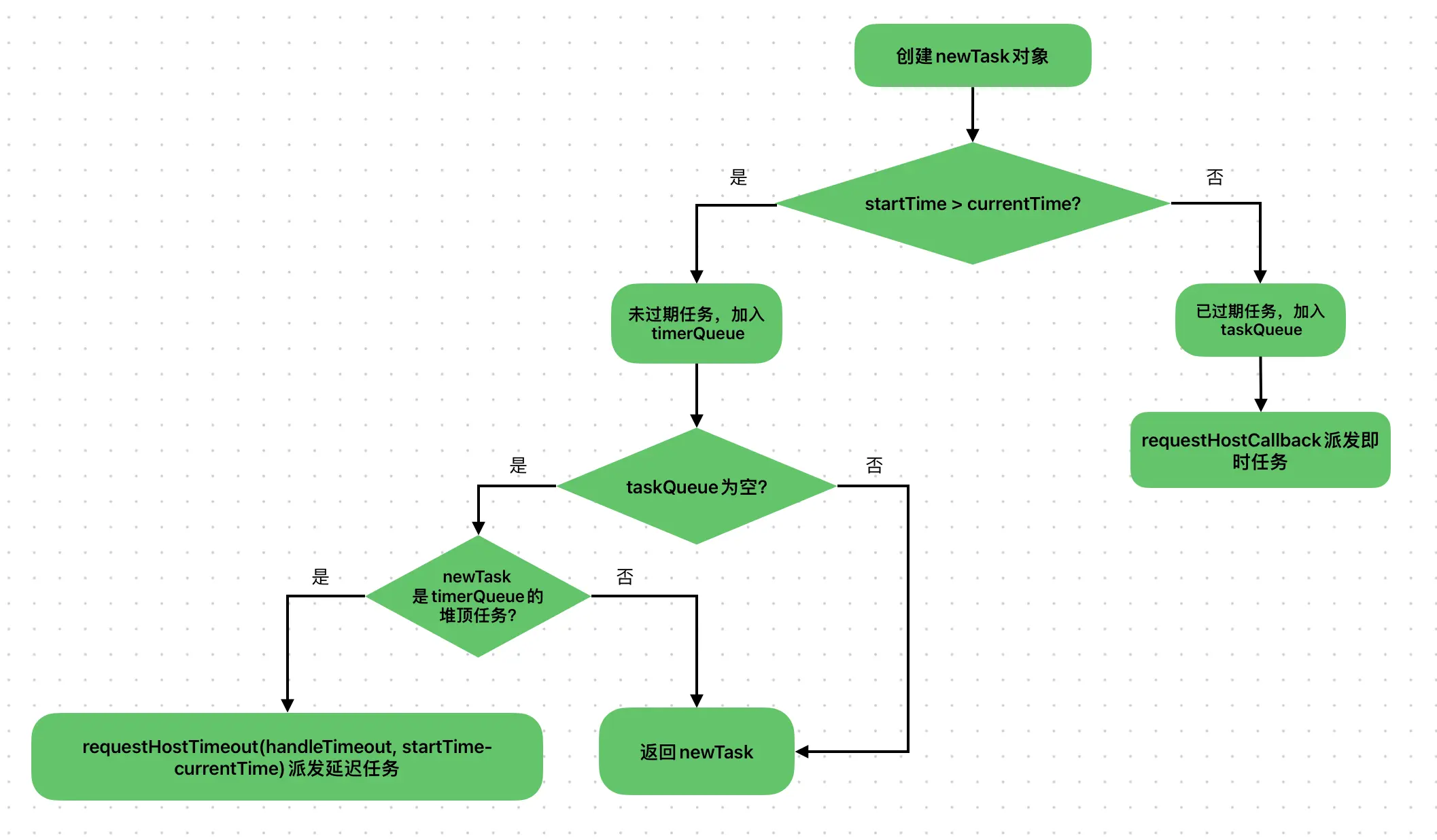
4.3 核心流程
第一步:获取浏览器当前状态
requsetIdleCallback是谷歌浏览器提供的一个API,在浏览器有空余时间时会调用requsetIdleCallback的回调。
requsetIdleCallback(callback,{timeout});
- callback:回调函数
- timeout:超时时间
第二步:任务切片(时间分片)
React底层会把任务分为若干个小任务,每次只执行一个小任务,执行完会去请求浏览器的空闲帧,不仅可以有序执行还不会阻塞浏览器渲染。
第三步:调度任务
React Scheduler通过requsetIdleCallback向浏览器做一帧一帧的请求,等到浏览器有空余帧,则执行更新队列中的任务。
4.4 requsetIdleCallback实现
React底层通过MessageChannel实现了一个requsetIdleCallback,可以兼容不同的浏览器系统。底层原理参考宏任务在事件循环中的执行。如果当前环境不支持MessageChannel,会自动开启setTimeout的降级方案。
为什么setTimeout(fn,0)时间间隔是4ms?
因为浏览器本身也是基于event loop的,如果浏览器允许0ms,可能会导致一个很慢的js引擎不断被唤醒,从而引起event loop阻塞,对于用户来说就是网站无响应。所以chrome 1.0 beta更改限制为1ms,但是后来发现1ms也会导致CPU spinning,计算机无法进入睡眠模式,经过多次实验后,Chorme团队选定了4ms
React团队觉得4ms过长,所以没有优先采用setTimeout,而是将其作为 降级方案使用。
什么是MessageChannel,有什么优点?怎么使用呢?
MessageChannel允许在不同的浏览上下文,比如window.open()打开的窗口或者iframe等之间建立通信管道,并通过两端的端口(port1和port2)发送消息。MessageChannel 底层实现以DOM Event的形式发送消息,所以它属于异步的宏任务,会在下一个事件循环的开头执行,并且执行的时机早于setTimeout。
我们熟悉的web worker跟主线程的通信就是基于MessageChannel实现的。
const { port1, port2 } = new MessageChannel();
port1.onmessage = function (event) {
console.log('收到来自port2的消息:', event.data); // 收到来自port2的消息: pong
};
port2.onmessage = function (event) {
console.log('收到来自port1的消息:', event.data); // 收到来自port1的消息: ping
port2.postMessage('pong');
};
port1.postMessage('ping');
第四章 React事件系统
1. 原生事件系统
W3C 标准约定了一个事件的传播过程要经过以下3个阶段:
- 事件捕获阶段
- 目标阶段
- 事件冒泡阶段
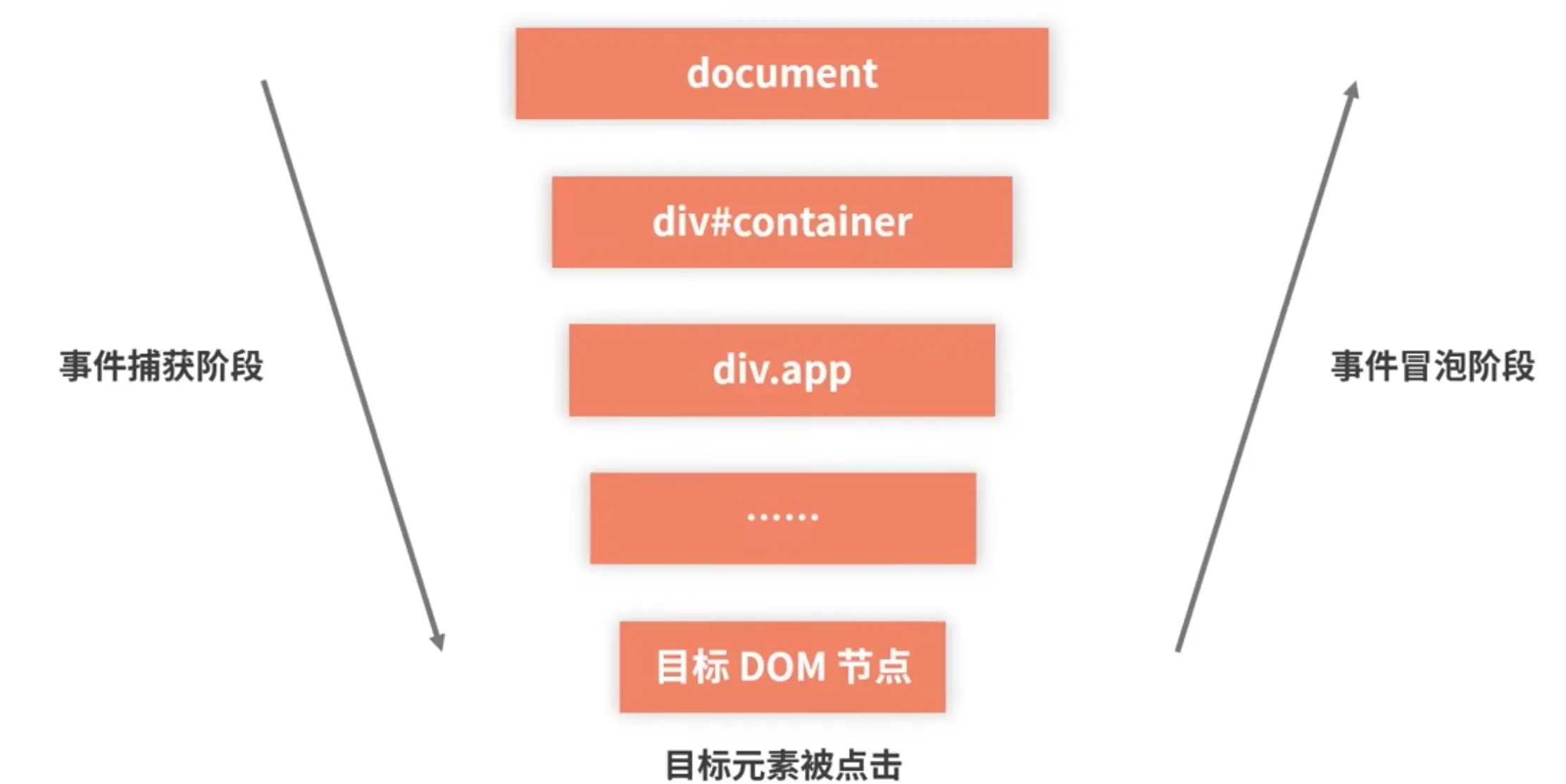
事件委托:把多个子元素的同一类型的监听逻辑合并到父元素上,通过一个监听函数来管理的行为。将事件绑定在父元素上,利用事件冒泡原理,通过e.target判断是否为目标元素,从而决定是否触发事件。
2. 合成事件系统
React 为了兼容不同浏览器,开发了一套自己的事件系统。
<div
onClick = {outerClick} // 冒泡阶段执行
onClickCapture={outerClickCapture} // 捕获阶段执行
/>
React Hook中每个方法的上下文都指向该组件实例,会自动绑定this为当前组件,并且React会对this的引用进行缓存,以此优化CPU和内存。但class组件和纯函数组件的自动绑定会失效,需要通过bind、构造器内声明、箭头函数手动处理this指向。
- 统一绑定在document或外层容器上
当事件在具体的DOM节点上被触发后最终都会冒泡到document上,document上所绑定的统一事件处理程序会将事件分发到具体的组件实例。
- 合成事件
React事件系统中将原生事件组合,形成合成事件。
合成事件在底层抹平了不同浏览器的差异,在上层面向开发者暴露统一的、稳定的、与DOM原生事件相同的事件接口。
虽然合成事件并不是原生DOM事件,但它保存了原生DOM事件的引用。可以通过e.nativeEvent获取对应的原生事件。
React合成事件系统使React掌握绝对的主动权。
- 阻止冒泡和默认行为
React合成事件系统可以看做原生DOM事件系统的子集,所以在原生事件中阻止冒泡行为,可以同时阻止React合成事件的传播,反之则不行。
React中阻止原生事件传播使用ev.stopPropagation()和return false,阻止合成事件传播使用stopPropagation(),阻止默认行为使用ev.preventDefault()。
3. 事件系统工作流
- 事件绑定
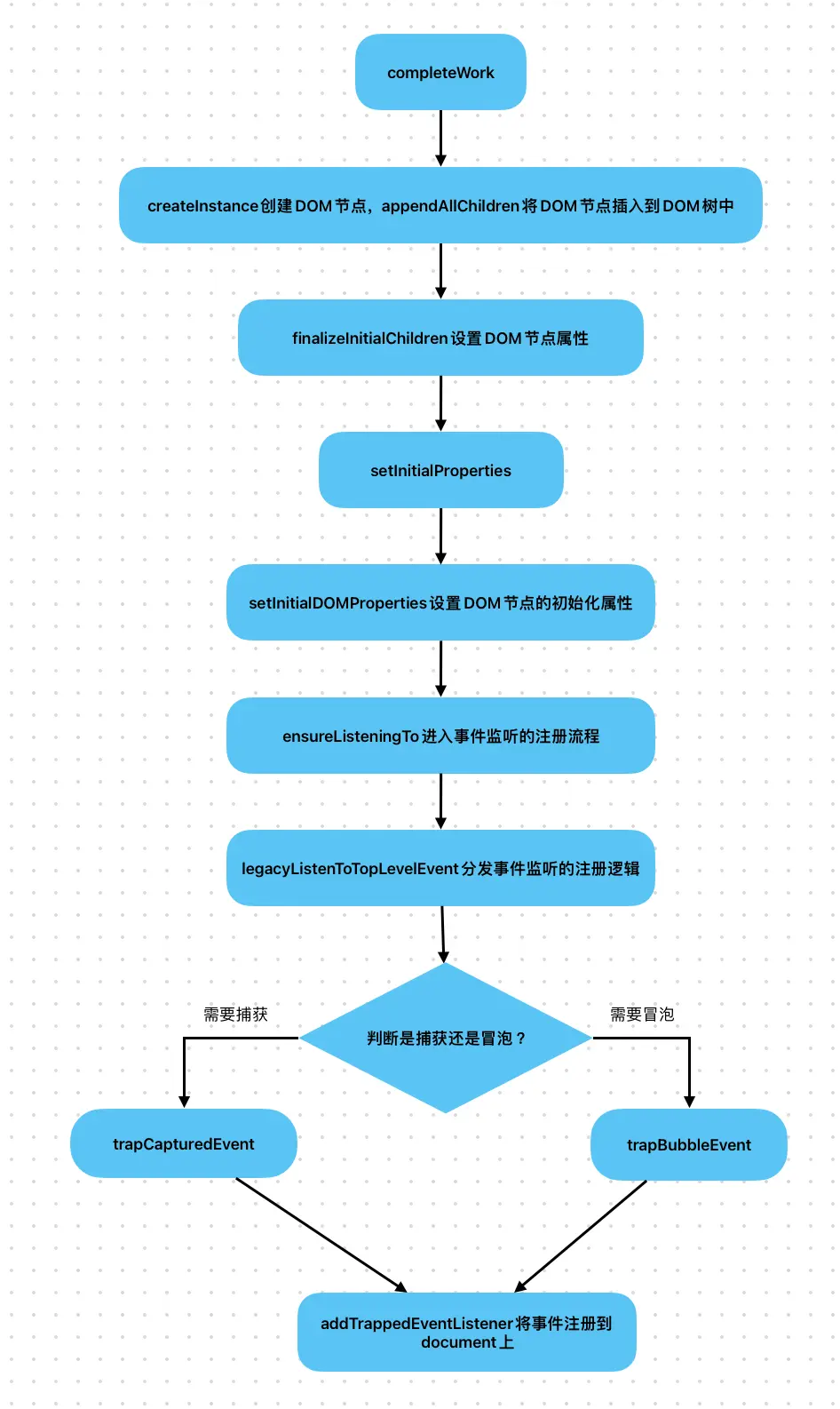
事件的绑定是在completeWork中完成的。
completeWork内部有三个关键动作作:
- 创建DOM节点(createlnstance)
- 将DOM节点插入到DOM树中(appendAllChildren)
- 为DOM节点设置属性(finalizelnitialChildren)
⚠️:由于React注册到document上的并不是某一个DOM节点对应的具体回调逻辑,而是一个统一的事件分发函数。所以即使同一事件存在多个回调函数,document也只会注册一次监听。
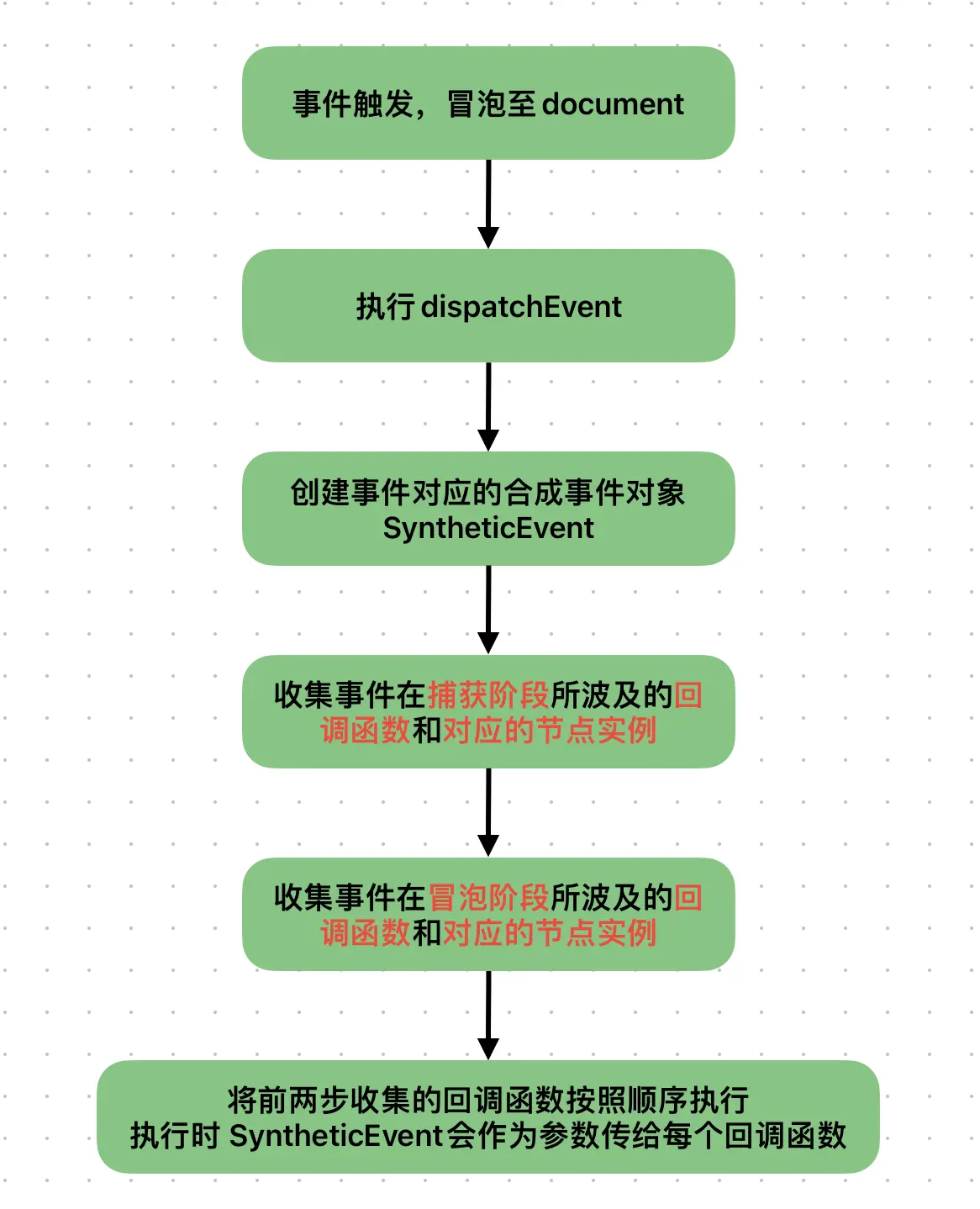
- 事件触发
事件触发的本质是对dispatchEvent函数的调用。
4. 合成事件系统的优点
- 事件可控性
React的事件处理函数不会直接绑定到真实DOM节点上,而是把所有事件都绑定到结构的最外层(React17、18绑定到root元素,React16绑定到document),使用一个统一的事件监听器管理。
React的这种机制使React可以感知事件的触发,并且让事件变得可控,方便外层App统一处理事件。
在React 事件系统触发的事件,ExecutionContext会合并EventContext,在执行上下文中通过EventContext判断是否在事件内部触发的更新,从而实现legacy模式下的批量更新操作。
- 跨平台兼容
React独立的事件系统将原生DOM元素和事件执行函数隔离开来,统一管理事件,使得事件的触发不是在DOM层面而是在JS层面,实现了React跨平台兼容能力。
- 事件合成机制
React中元素绑定的事件不是原生事件,而是合成事件。一个合成事件可能包括多个原生事件,React基于Virtual DOM实现了一个SyntheticEvent合成事件层,定义的事件处理器会接收到一个SyntheticEvent对象的实例,其符合W3C标准,同样具备事件的冒泡机制。底层React会用一个对象记录React事件和合成的原生事件的映射。
- 事件委托
React的事件处理函数不会直接绑定到真实DOM节点上,而是把所有事件都绑定到结构的最外层(React17、18绑定到root元素,React16绑定到document),使用一个统一的事件监听器管理。事件监听器上维持了一个映射,保存所有组件内部的事件监听和处理函数。当组件挂载或卸载的时候,在这个事件监听器上插入或删除一些对象;当事件发生时,事件监听器在映射里找到真正的事件处理函数并调用。
- 事件传播
合成事件捕获阶段执行 => 原生事件监听 => 合成事件冒泡阶段执行
<button
onClickCapture={()=>{console.log('合成事件捕获阶段执行')}}
onClick={()=>{console.log('合成事件冒泡阶段执行')}}
>
按钮命名
</button>
button.addEventListener('click',()=>{console.log('原生事件监听')});
- 事件系统执行顺序
export const ListContent = ()=>{
function outerClick() {
console.log('--------outer合成事件---冒泡----');
}
function outerClickCapture() {
console.log('--------outer合成事件---捕获----');
}
function innerClick(e:any) {
console.log('--------inner合成事件---冒泡----');
}
function innerClickCapture(e:any) {
console.log('--------inner合成事件---捕获----');
}
useEffect(() => {
/**
* 原生事件的冒泡和捕捉
*/
document.addEventListener('click', (ev) => {
console.log('document原生事件------冒泡');
});
document.addEventListener('click', (ev) => {
console.log('document原生事件------捕获');
},true);
document.body.addEventListener('click', () => {
console.log('body原生事件------冒泡');
});
document.body.addEventListener('click', () => {
console.log('body原生事件------捕获');
}, true);
document.getElementById('root')?.addEventListener('click', () => {
console.log('root原生事件------冒泡');
});
document.getElementById('root')?.addEventListener('click', () => {
console.log('root原生事件------捕获');
}, true);
document.querySelector('.outer')?.addEventListener('click', () => {
console.log('outer原生事件------冒泡');
});
document.querySelector('.outer')?.addEventListener('click', (ev) => {
console.log('outer原生事件------捕获');
}, true)
document.querySelector('.inner')?.addEventListener('click', (ev) => {
console.log('inner原生事件------冒泡');
});
document.querySelector('.inner')?.addEventListener('click', (ev) => {
console.log('inner原生事件------捕获');
}, true);
});
return(
<div>
<div className = 'outer' onClick = {outerClick} onClickCapture={outerClickCapture} >
outer
<div className = 'inner' onClick = {innerClick} onClickCapture={innerClickCapture} >
inner
</div>
</div>
</div>
)
}

第五章 React性能优化
React18为了解决CPU瓶颈、I/O瓶颈设计了useDeferred Value、useTransition等
1. 性能优化方式
- 使用shouldComponentUpdate规避多余的更新逻辑
- PureComponent + Immutable.js
- React.memo 与 useMemo
2. shouldComponentUpdate
React组件会根据shouldComponentUpdate的返回值来决定是否执行该方法之后的生命周期,进而决定是否对组件进行re-render(重渲染)。
默认值为true,即无条件的重渲染。
shouldComponentUpdate可以根据接收的新的props和state决定是否更新组件,由于shouldComponentUpdate采用的是浅比较,如果引用类型的内存地址没有改变,但是属性值改变了,会影响其判断。可以结合Immutable Data使用。
适用场景:
- 父组件更新引发的子组件无条件更新
- 组件内部的state变化引发的组件更新
shouldComponentUpdate(nextProps,nextState){
// text没有改变则不更新
if(nextProps.text === this.props.text){
return false;
}
return true;
}
3. PureComponent
PureComponent内置了“在shouldComponentUpdate中对组件更新前后的props和state进行浅比较,并根据浅比较的结果决定是否需要继续更新流程”。
export const class APP extends React.PureComponent{
... ...
}
- 基本数据类型:比较两次的值是否相等
- 引用数据类型:比较两个值的引用是否相等
⚠️:如果数据没变,但是引用变化,则PureComponent还是会进行无用的重渲染;如数据变了,但是引用没变,则PureComponent不会重渲染,导致页面显示错误;
为了解决这个问题,需要借助于Immutable.js。
4. Immutable.js
Immutable Data表示创建后不能再更改的数据,对Immutable对象进行修改、添加、删除操作都会返回一个新的Immutable对象。Immutable的实现原理是持久化的数据结构,在使用旧数据创建新数据时,同时保证旧数据可用且不变。该数据类型避免了深拷贝复制带来的性能损耗。
Immutable Data使用了结构共享,如果对对象中一个节点进行更新,只修改当前节点和受他影响的父节点,其他节点进行共享。
常用数据类型有Map、List、ArraySet
常用的判读方法:is
优点:降低数据变化造成的复杂度、节省内存
import {Map,is} from 'immutable';
let a = Map({
select: 'users',
filter: 'name'
});
let b = a.set('select','people');
a === b // false
a.get('filter') === b.get('filter') // true
is(a) === is(b) // true
5. React.memo
memo 是个高阶组件, 结合了 PurComponent 和 shouldComponentUpdate 功能,会对传入的 props 进行浅比较,从父组件直接隔断子组件渲染。
- 缓存机制
- 父组件重新渲染,没有被 memo 包裹的子组件也会重新渲染
- 被 memo 包裹的组件只有在 props 改变后,才会重新渲染
- memo 对新旧 props 做浅比较,对于引用类型的数据如果发生了更改,需要返回一个新的地址
- memo不能避免组件内部state和context更新引发的重新渲染
- 浅比较
React底层使用的是shallowEqual,其比较流程如下:
-
比较新老props或者state是否相等,相等就不更新组件
-
判断新老props或者state是否为对象,不是的话直接更新组件
-
通过Object.keys将新老props或者state的属性名key变成数组,判断数组长度是否相等,不相等直接更新组件
-
遍历老props或者state,判断与之对应的新props或者state,是否与之相等(引用内存地址相等),全部相等则不更新组件,否则更新组件
-
场景应用
import React, { useState } from "react";
const Child = () => <div>{console.log("子组件又渲染")}</div>;
const List = () => {
const [flag, setFlag] = useState(false);
return (
<>
<Child />
<div onClick={() => setFlag(!flag)}>
{flag ? "显示" : "隐藏"}
</div>
</>
);
};
export default List;
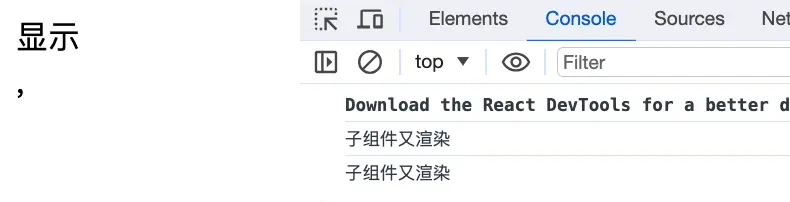
点击按钮,父子组件都重新渲染了
import React, { useState } from "react";
const Child = React.memo(() => <div>{console.log("子组件又渲染")}</div>);
const List = () => {
const [flag, setFlag] = useState(false);
return (
<>
<Child />
<div onClick={() => setFlag(!flag)}>
{flag ? "显示" : "隐藏"}
</div>
</>
);
};
export default List;
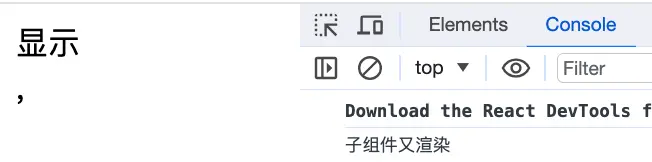
点击按钮,只有父组件重新渲染
- 缓存陷阱
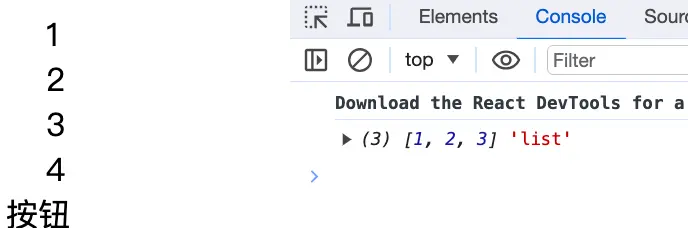
memo 对于新旧 props 的比较是浅比较,当一个引用类型的 props 改变时,只要它的地址没有发生改变,那么就算 props 中某一项数据发生了改变,那么被 memo 包裹的组件是不会重新渲染的
当点击按钮,父组件的状态已经更新,但是子组件没有更新
const Child = React.memo((props:any) => (
<div>
{props.list.map((item:any) => (
<div style={{marginLeft: '20px'}}> {item} </div>
))}
</div>
));
const List = () => {
const [list, setList] = useState([1,2,3]);
const handleClick = ()=>{
list.push(4)
setList(list);
console.log(list,'list');
}
return (
<>
<Child list={list}/>
<div onClick={handleClick}>按钮</div>
</>
);
};
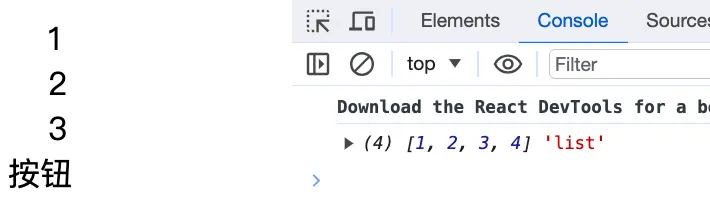
解决办法:改变props的引用地址,即返回一个新的数组
const handleClick = ()=>{
setList([...list, 4])
console.log(list,'list');
}
6. useMemo
useMemo可以理解为“无副作用的因变量”
const y = useMemo(()=> x+1,[x])
useMemo 会记录上一次的返回值并将其绑定在fiber对象,只要组件不销毁,缓存值就一直存在,如果依赖项改变,会重新计算缓存值。
useMemo接受两个参数 callback 和 deps,useMemo 执行callback 后,会返回一个结果,并把这个结果缓存起来。当 deps 依赖发生改变的时候,会重新执行 callback 计算并返回新的结果,否则就使用缓存的结果。
useMemo是在渲染期间完成计算的,所以其返回值可以直接参与渲染。
1)缓存机制
- 依赖数组不为空:组件首次渲染时计算值,依赖项不变会始终返回初始值,依赖项发生改变会重新计算结果并缓存
- 依赖数组为空:组件首次渲染时计算值,后续渲染将重用这个值,而不进行重新计算
- 省略依赖数组:相当于没有使用useMemo
2)特点
- useMemo 是对计算的结果进行缓存,当缓存结果不变时,会使用缓存结果
- useMemo 一般用于缓存复杂计算的结果
- useMemo搭配memo实现子组件重新渲染的性能优化
- 依赖数组中避免包含不稳定的值,如内联函数或对象,可能会导致不必要的重新计算
原因:父组件将引用类型传递给子组件,当子组件用 memo包裹,memo就会对 props 做浅比较,父组件重新渲染时,会在内存中开辟一个新的地址赋值给引用类型,引用类型的地址发生变化,子组件会重新渲染。所以需要使用useMemo对引用数据进行缓存。
3)适用场景

4)应用场景
当点击计算后,调用setNum后会重新渲染组件,从而导致computeResult也跟着重新计算了,浪费性能
const Parent = () => {
const [num, setNum] = useState(0);
const clickHadler = () => {
setNum(num + 1)
}
const computeResult = () => {
// 模拟需要花费时间的大量计算
for(let i = 0; i < 10000; i++) {}
}
return (
<>
{computeResult(),number值: {num}
<Button onClick={() => clickHadler()}>点击计算</Button>
</>
);
};
可以使用useMemo进行优化,从而减少不必要的状态更新
// 使用 useMemo 缓存计算的结果
const computeResult = useMemo(() => {
for(let i = 0; i < 10000; i++) {}
}, [])
7. useCallback缓存函数
缓存函数,当函数依赖项发生变化时会重新创建函数并返回新函数地址,否则会直接返回旧的回调函数地址,react hook中渲染性能优化的钩子函数。
useCallBack的底层不是在依赖不变的情况下阻止函数创建,而是在依赖不变的情况下不返回新的函数地址而返回旧的函数地址,不论是否使用useCallBack都无法阻止组件render时函数的重新创建。
1)缓存机制
- 依赖数组不为空:组件首次渲染时创建函数并返回函数地址,依赖项不变会始终返回旧函数地址,依赖项发生改变会重新创建新函数并返回新函数地址
- 依赖数组为空:组件首次渲染时创建函数并返回函数地址,后续渲染将始终用旧的函数地址,而不进行重新创建
- 省略依赖数组:相当于没有使用useCallback
2)特点
- useCallback 可以单独使用,但是单独使用的性能优化没有实质的提升,当父组件重新渲染时,子组件同样会渲染
- useCallback 需要配合 memo 一起使用,当父组件重新渲染时,缓存的函数的地址不会发生改变,memo 浅比较会认为 props 没有改变,因此子组件不会重新渲染
3)适用场景

8. PureRender强化
PureRender强化shouldComponentUpdate生命周期
可以在shouldComponentUpdate生命周期通过对nextProps与prevProps、nextState与prevState做浅比较,返回false阻止render方法执行,来减少不必要的更新,从而提升性能
import React,{Component} from 'react';
import PureRenderMixin from 'react-addons-pure-render-mixin';
class App extends Component {
constructor(props){
super(props);
this.shouldComponentUpdate = PureRenderMixin.shouldComponentUpdate.bind(this);
}
}
9. 强制更新
类组件的forceUpdate,函数组件改变内存地址,以及Context更新引发消费者更新等,都会造成React应用的强制更新。
10. 判断组件是否更新
判断一个组件是否更新可以通过如下流程:
第一步:判断组件内部是否开启优化策略,useMemo、useCallback等。如果使用useMemo或者useCallback,则会在其依赖项改变时才会重新计算缓存
第二步:判断子组件是否使用React.memo包裹,或者继承自pureComponent。如果class继承自pureComponent,则开启浅比较,返回值相等则不更新;如果使用React.memo包裹函数组件,继续判断是否传入第二个参数用来自定义判断流程,如果没有第二个参数,则使用浅比较,否则使用第二个参数返回值决定是否更新;
第三步:如果是类组件判断是否有shouldComponentUpdate生命周期。如果有的话判断返回值是否为true,true的话更新组件,否则不更新组件
第六章 Redux
1. Flux框架
Flux不是一个具体的框架,而是一套由FackBook团队提出的应用架构。这套架构约束的是应用处理数据的模式。
Flux将每个应用都划分为四部分:View、Store、Action、Dispatcher
- view视图层:表示用户界面,可以是任何形式的产物
- Action动作:视图层发出的消息,会触发应用状态改变
- Dispatcher派发器:负责对action进行分发
- Store数据层:存储应用状态的仓库,同时具备修改状态的逻辑
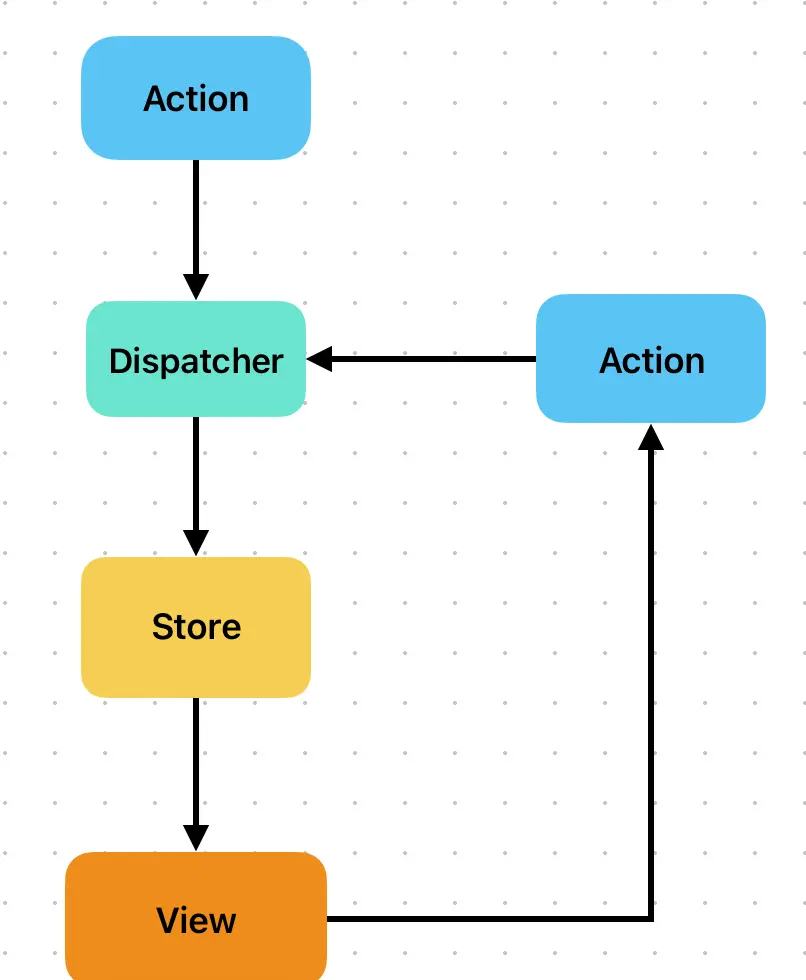
Flux最核心的原理是严格的单向数据流,Redux是Flux思想的产物,虽然没有完全实现Flux,但是却保留了单向数据流的特点。
2. Redux
2.1 核心元素
- Store:单一数据源,只读
- Action:对变化的描述
- Reducer:负责对变化进行分发和处理,并将新的数据返回给Store
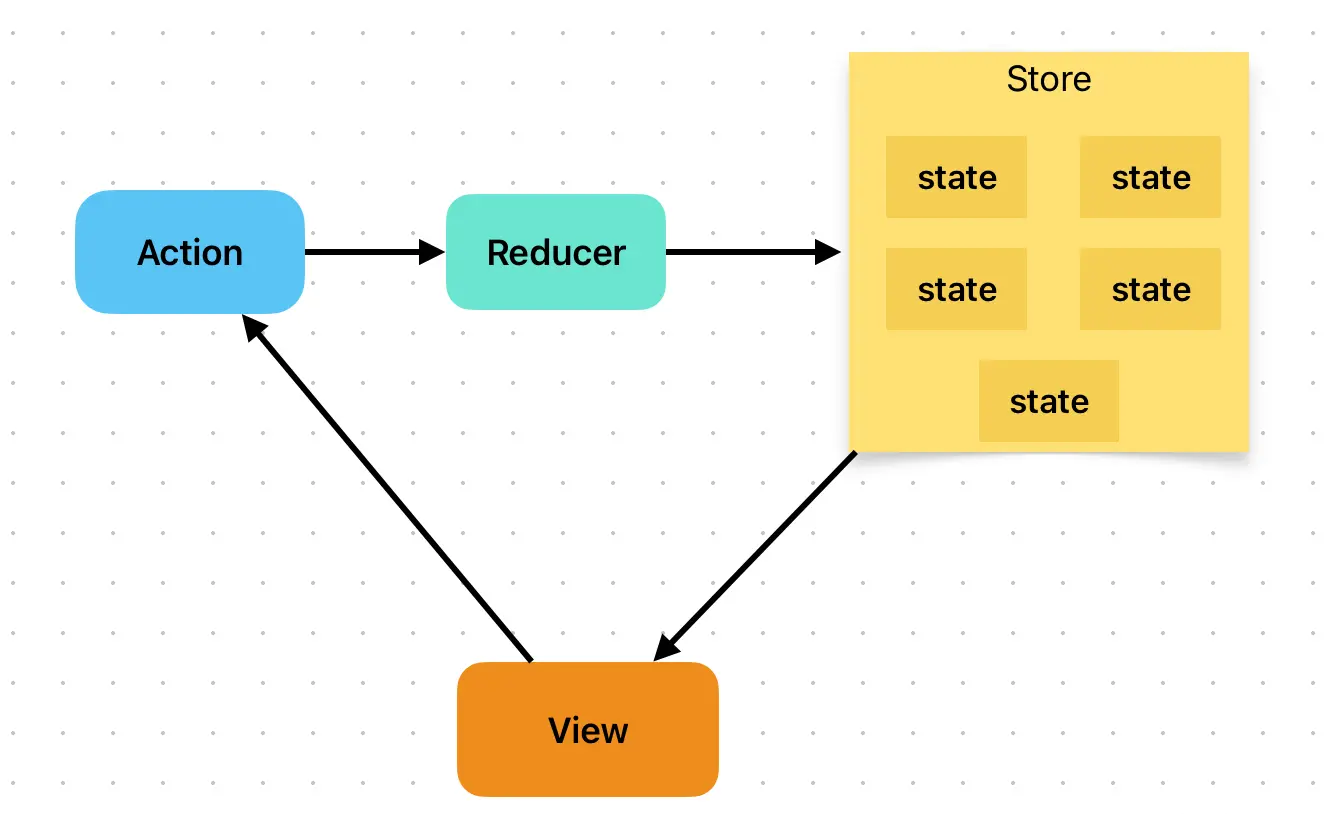
- reducer
reducer本质上是一个函数,负责响应action并修改数据。
reducer(previousState,action)=>{
if(previousState){
... ...
return newState
}else{
... ...
}
}
reducer根据previousState参数和action行为计算出新的newState
reducer优化:
- 拆分
根据独立的模块拆分出单独的reducer

- 合并

- 统一管理actionType
- createStore
通过createStore方法创建store对象。
const store = createStore(reducers);
createStore本身包含四个方法:
- getState:获取当前store中的状态
- dispatch(action):分发一个action,并返回这个action,这是唯一能改变store中数据的方式
- subscribe(listener):注册一个监听者,在store发生变化时调用
- replaceReducer(nextReducer):更新当前store里的reducer,一般只会在开发模式中调用此方法
export function createStore(reducers, initialState, enhancer){}
createStore利用前两个参数进行createStore的调用。
createStore利用enhancer对createStore能力做增强,并返回增强后的createStore(利用高阶函数的原理)
export function createStore(reducers,initialState,enhancer){
// 认为没有传默认state值
if(typeof initialState === 'function' && typeof enhancer === 'undefined'){
enhancer = initialState;
initialState = undefined;
}
if(typeof enhancer !== 'undefined'){
if(typeof enhancer !== 'function'){
throw new Error('错误')
}
// 高阶函数原理
return enhancer(createStore)(reducers,initialState)
}
}
接收createStore作为参数传入 ,对createStore的能力做增强,并返回createStore,然后再将reducers,initialState作为参数传递给增强后的createStore,最终得到store。
- Action Type
整个store中的action type值不能重复,需要达到全局唯一性
1)命名空间(Namespacing)
为每个模块或功能区分配一个独立的命名空间,以确保它们的 action type 常量不会发生冲突。例如将模块名作为前缀,USER_FETCH_REQUESTED
2)统一文件管理
将所有模块的 action type 常量定义放在一个统一的文件中,以避免不同文件之间的命名冲突
3)使用工具库
使用工具库来自动化处理 action type 常量的生成。一些常用的工具库有 redux-actions 和 redux-toolkit,它们简化 Redux 开发的功能,可以自动生成唯一且不会重复的 action type 常量
4)唯一性检查
可以编写自定义的工具函数或脚本,在构建或开发过程中对 action type 常量进行唯一性检查
2.2 工作流
获取状态:任何组件都可以以约定的方式从Store读取全局状态
修改状态:任何组件都可以通过合理的派发Action来修改全局状态
2.3 Redux原则
单一数据源:将所有状态保存在一个对象中,可以随时提取整个状态进行持久化,也为服务端渲染提供了可能
状态只读:reducer根据当前触发的action对应用状态进行迭代,不是直接修改应用状态而是返回一个全新状
状态修改均由纯函数完成:相同的输入会有相同的输出
2.4 Redux使用
- Provider
Provider接收一个store作为props,是整个应用最外层的React组件。
其实现大致流程是:在constructor中拿到props中的store,并挂载到当前实例上。同时定义getChildContext方法,该方法定义了自动沿用组件传递的特殊props。

- connect
export default function connect(mapStateToProps, mapDispatchToProps, mergeProps, options={}){}
- mapStateToProps:定义了需要从Redux中获取哪些状态作为props传递给当前组件
- mapDispatchToProps:将actionCreator与dispatch绑定在一起,并将其作为props传递给当前组件
- mergeProps:对接收到的所有props进行分类,命名和重组
- options:配置项,一般包含两方面
pure:true
connect在shouldComponentUpdate中使用浅比较减少不必要的重新渲染
withRef:true
connect保存对装饰组件的refs引用,可以通过getWrappedInstance获取最中的DOM节点
3. 工作原理
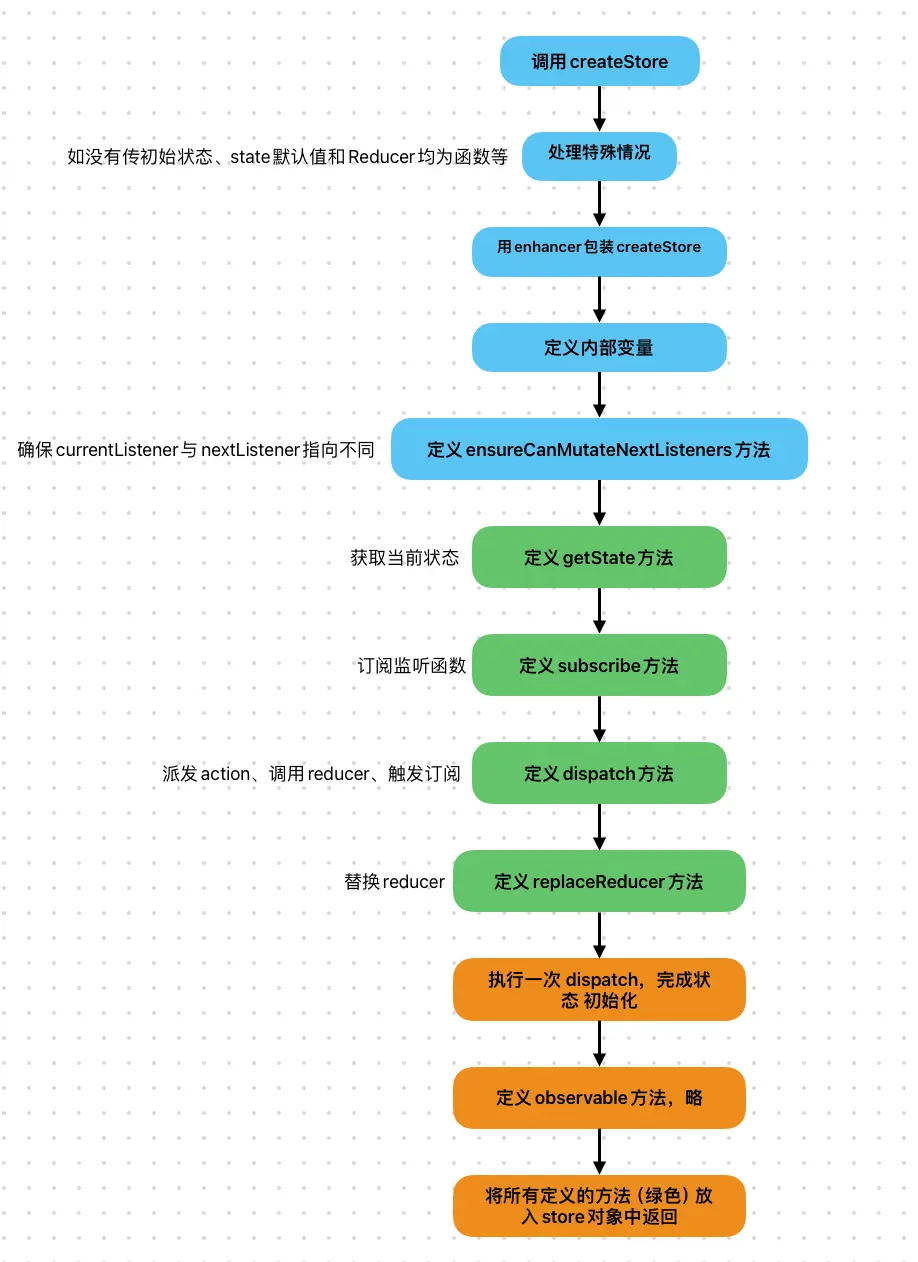
3.1 createStore
createStore方法是在使用Redux时最先调用的方法,是整个流程的入口。同时也是 Redux中最核心的API。
3.2 dispatch
dispatch动作,主要工作即“将Redux核心三要素串联起来”。
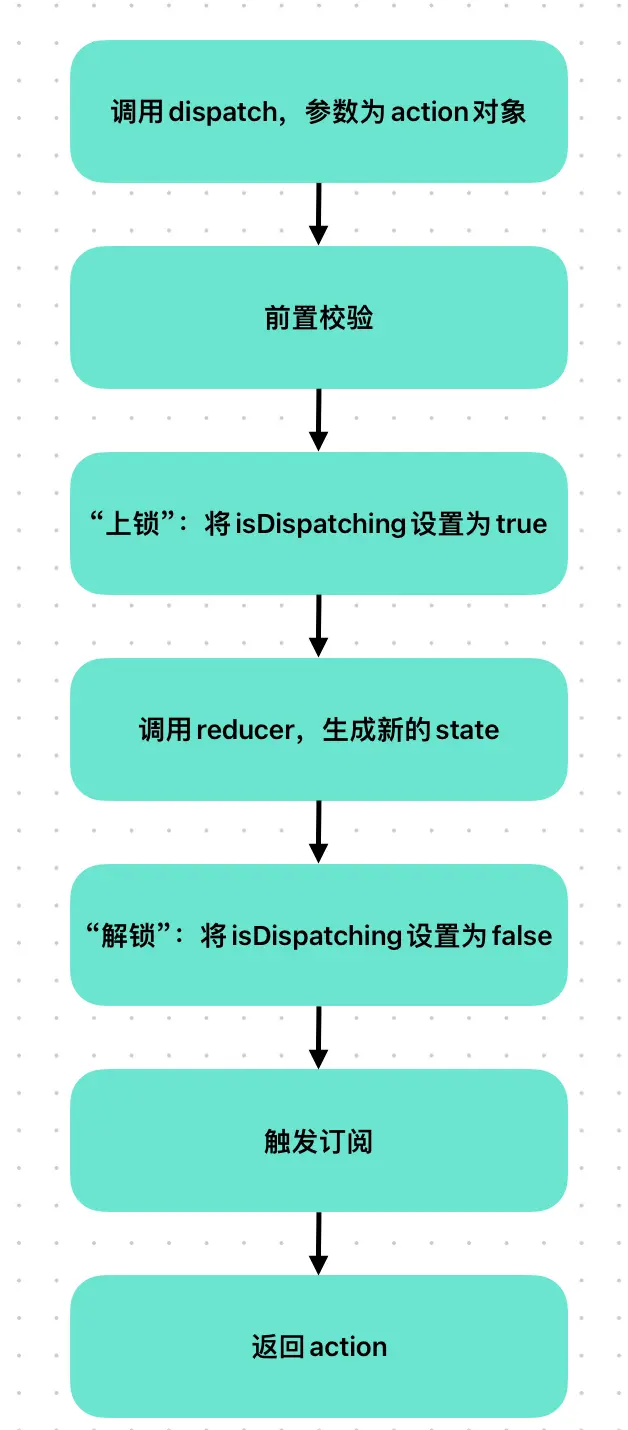
通过上锁,避免套娃式的dispatch
try{
isDispatching = true;
currentState = currentReducer(currentState,action);
}finally{
isDispatching = false;
}
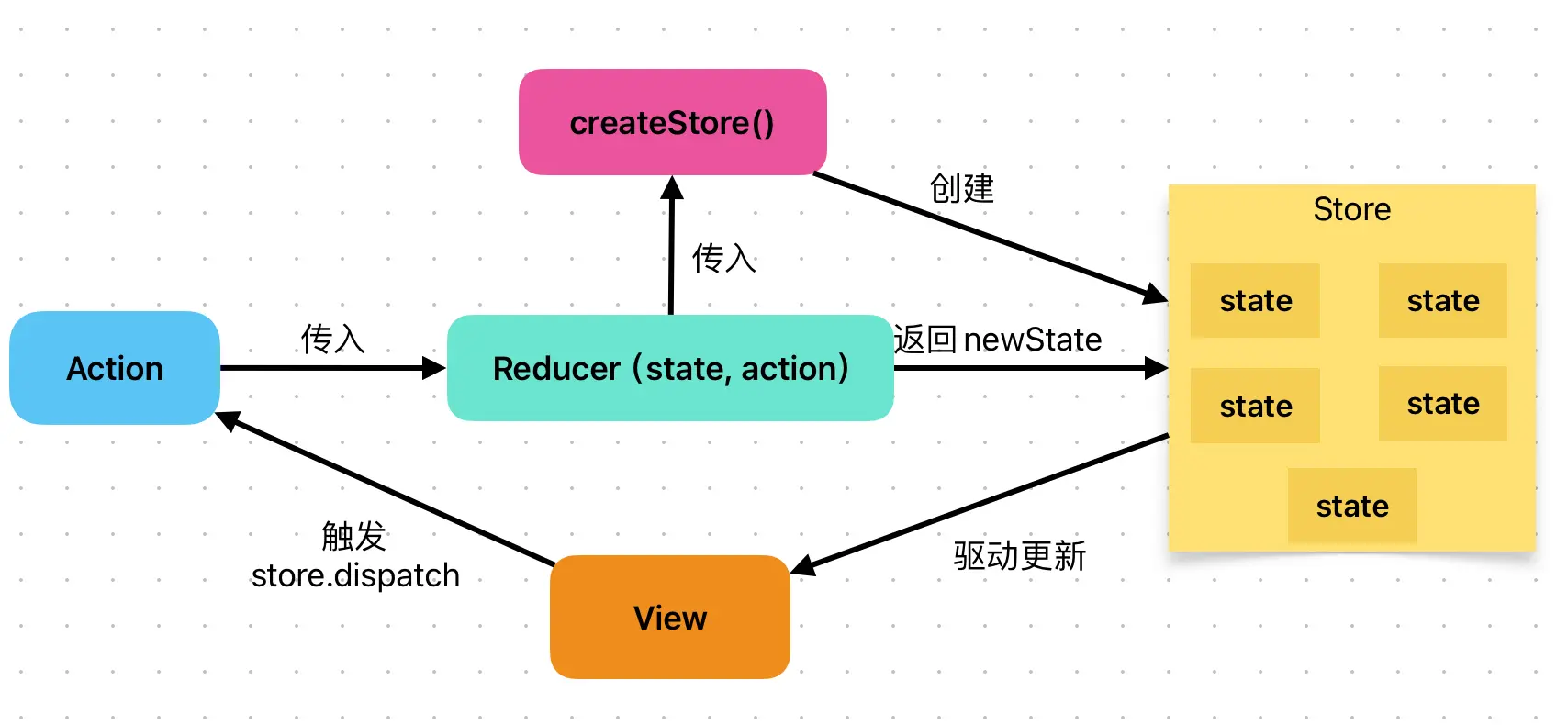
Redux完整流程如下:
3.3 subscribe
在store对象创建成功后,通过调用store.subscribe注册监听函数。
当dispatch action发生时,Redux会在reducer执行完毕后,将listeners数组中的监听函数逐个执行。
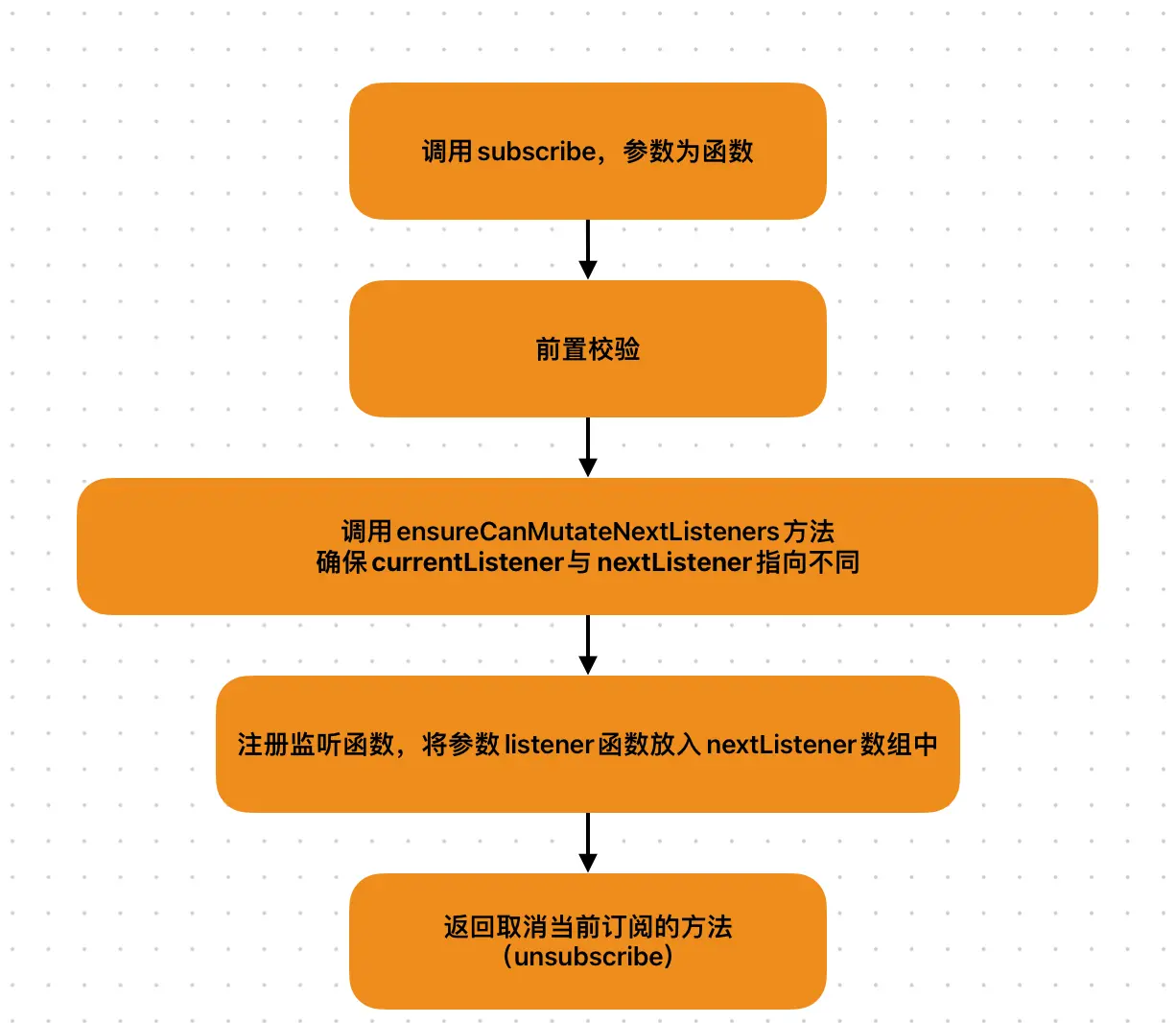
- nextListener:订阅、触发、解除订阅操作的均是nextListener
- currentListener:记录当前正在工作的listeners数组的引用,将它与可能发生改变的nextListeners区分开来,以确保监听函数在执行过程中的稳定性
4. 中间件
const store = createStore(
reducer,
initial_state,
applyMiddleWare(middleWare1,middleWare2,...)
)
applyMiddleWare的作用就是向store中注入中间件(enhancer包装createStore)。
中间件是指可以增强createStore的工具,在Redux中所有的更新都是同步执行的,如果想要异步处理更新流程,则需要借助中间件。
redux-thunk就是一个异步Action解决插件。
中间件的工作流程图:
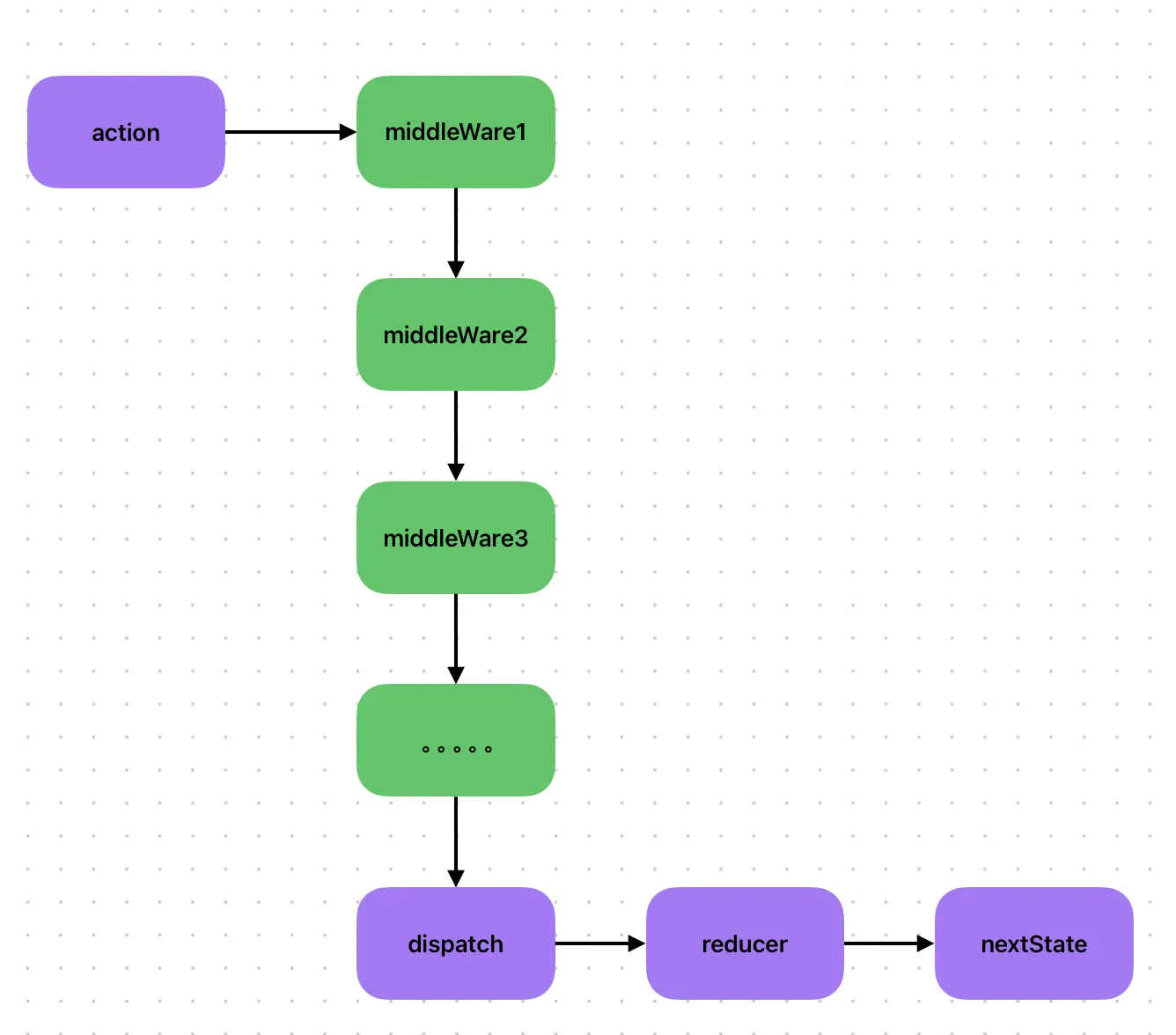
中间件的执行时机:action分发之后、reducer执行之前。
中间件的执行前提:利用applyMiddleWare对dispatch函数进行改写,使其在触发reducer之前,会先执行对redux中间件的链式调用。
第七章 React-router
1. 路由模式
React Router与React的很多特性保持一致,在React中,组件就是一个方法,props作为参数传入方法,当props更新时会触发方法的执行,从而重新绘制View。在React Router中,同样可以把Router看作是一个方法,location作为参数传入方法,返回的结果同样是一个View。
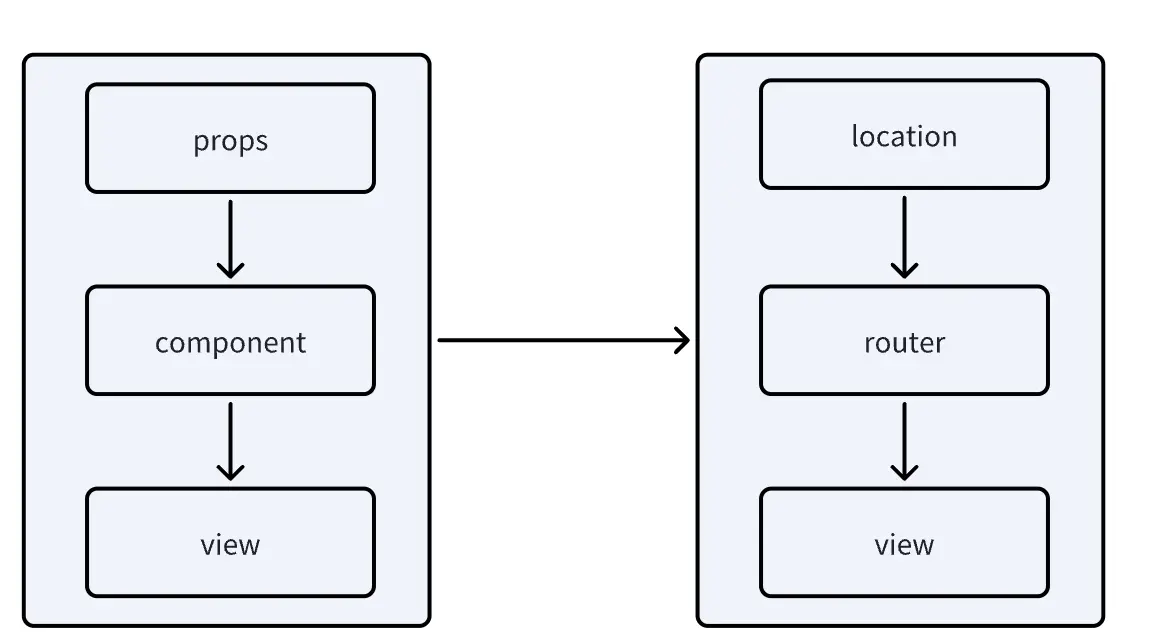
当用户在任何路由下刷新页面,浏览器都可以根据当前URL进行资源定位,不会出现白屏问题。
- hash模式:改变URL中#后面的部分,实现组件的切换
// 感知hash变化
window.addEventListener('hashChange',functionn(event){
...
},false)
- history模式:改变整个URL,实现组件切换
// 追加记录
history.pushState(data[,title][,url]);
// 修改记录
history.replaceState(data[,title][,url])
// 感知state变化
window.addEventListener('popState',functionn(event){
...
},false)
1.1 声明式路由
ReactRouter继承了声明式编程特点,允许使用JSX标签书写路由
// 当前页面url为/login时,React会渲染Login这个组件
import { Router,Route,browserHistory} from 'react-router';
const routes = (
<Router history={browserHistory}>
<Route path="/login" component={<Login />} />
</Router>
)
1.2 嵌套路由及路径匹配
在许多单页应用中,嵌套路由是最常见的路由模式。
例如页面有的顶栏、侧边栏、列表,点击具体列表卡片跳转时顶栏和侧边栏需要复用
import { Router,Route,IndexRoute,browserHistory} from 'react-router';
const routes = (
<Router history={browserHistory}>
<Route path="/" component={<App />}>
<IndexRoute component={< List/>} />
<Route path="/list/:listID" component={<Case />} />
</Route>
</Router>
)
App组件具有顶栏和侧边栏的功能,React Router自动根据当前url决定匹配列表页还是详情页
- url = /:则匹配List组件
- url = /list/1:则匹配Case组件
1.3 支持多种路由切换模式
hashHistory:利用hashChange改变#后面的url,浏览器兼容性较好,但是url中会增加#
import { Router,Route,hashHistory} from 'react-router';
browserHistory:利用history.pushState更新整个url,需要服务端配置,解决任意路径刷新的问题
import { Router,Route,browserHistory} from 'react-router';
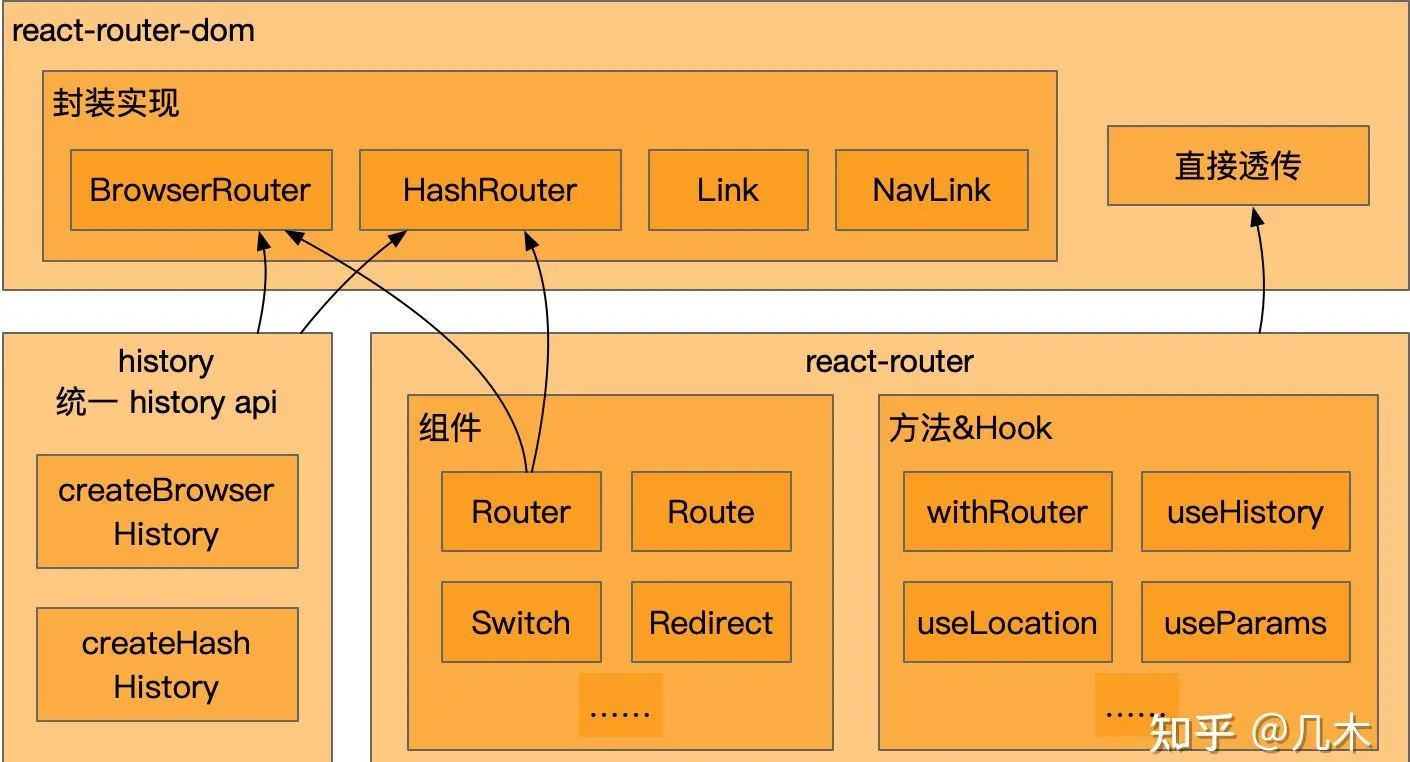
2. react-router-dom
在浏览器宿主下进一步封装react-router,集成了history与react-router
初始化了<BrowserRouter>,<HashRouter>,<Link>等可以直接使用的组件
3. react-router-redux
- 绑定Router与Redux store
Redux作为单一的状态管理工具,管理全局状态,其中路由也是全局状态的一种,所以也应该由Redux管理,通过Redux的方式改变路由。
React Router Redux提供了syncHistoryWithStore实现Redux store与Router的绑定,它接收两个参数:history和store,返回一个增强的history对象。
将增强的history对象作为props传给React Router中的<Router>组件,从而实现观察路由变化改变store的能力。
import { browserHistory} from 'react-router';
import { syncHistoryWithStore} from 'react-router-redux';
import { reducers} from 'react-redux';
const store = createStore(reducers);
const history = syncHistoryWithStore(browserHistory,store);
- 用Redux切换路由
首先对store进行增强
import { browserHistory} from 'react-router';
import {routerMiddleware} from 'react-router-redux';
const middleware = routerMiddleware(browserHistory);
const store = createStore(
reducers,
applyMiddleware(middleware)
);
- 通过action切换路由
import {push} from 'react-router-redux';
store.dispatch(push('/home'));
4. 路由跳转
- 核心元素
- BrowserRouter:路由器,根据映射关系匹配新的组件。分为BrowserRouter和HashRouter
- Route:路由,定义组件与路径的映射关系。包括Route、Switch等
- Link:导航,改变路径。如Link、NavLink、Redirect
- 路由器
- BrowserRouter:通过H5的history API处理URL跳转
- HashRouter:通过URL的hash属性处理路由跳转
第八章 React延伸
1. 不能在循环或条件语句中使用Hook
React底层通过数组和下标保存Hook,每次Hook 的调用都会对应一个全局的 index 索引,通过这个索引去当前运行组件 currentComponent 上的 _hooks数组中查找保存的值,也就是 Hook 返回的 [state, useState]等。
// 第一次调用 currentIndex 为 0
if (Math.random() > 0.5) {
useState('first')
}
// 第二次调用 currentIndex 为 1
useState('second')
如上所示例子中,假设第一次调用时Math.random()>0.5,则底层的_hooks数组结构如下:
_hooks: [
{ value: 'first', update: function },
{ value: 'second', update: function },
]
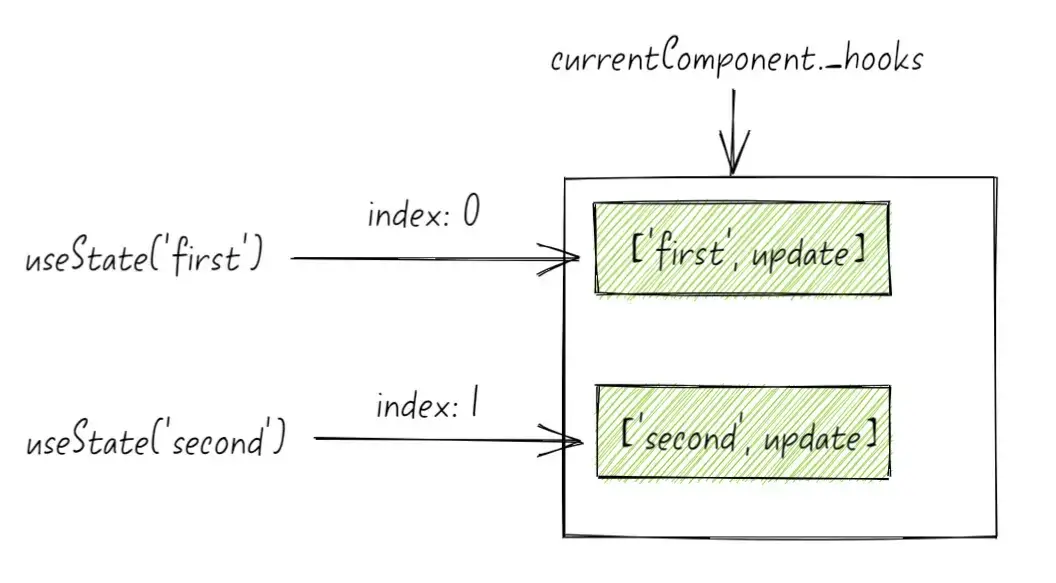
假设第二次渲染的时候,Math.random() < 0.5,第一个 useState 不会被执行,只有第二个useState执行,那么它对应的全局 currentIndex 会是 0,这时候去_hooks[0]中拿到的却是 第一次执行对应的状态,就会造成渲染混乱
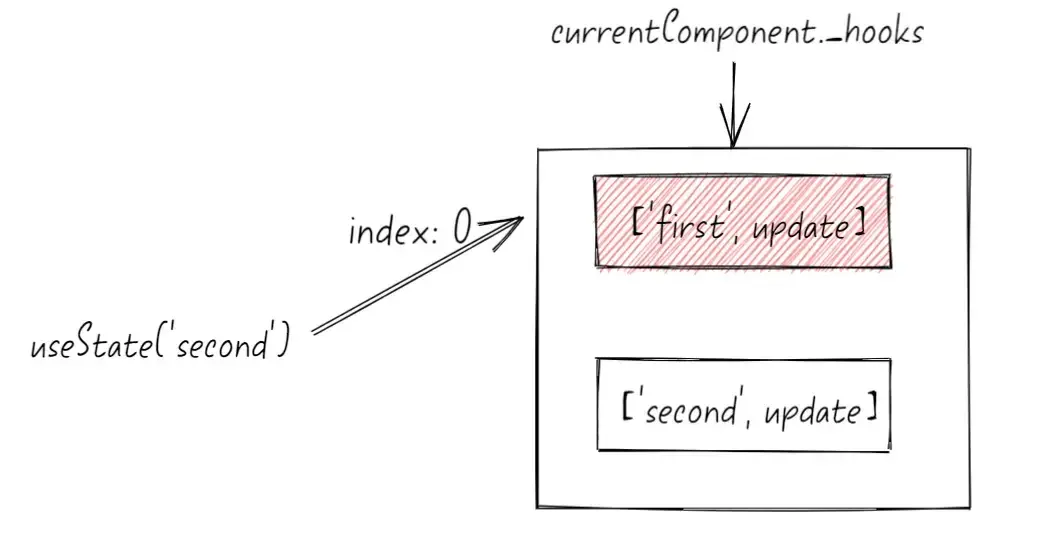
所以如下写法是不被建议的
export default function App() {
if (Math.random() > 0.5) {
useState(10000)
}
const [value, setValue] = useState(0)
return (
<div>
<button onClick={() => setValue(value + 1)}>+</button>
{value}
</div>
)
}
2. 定时器hook实现
入门案例:利用react hook实现一个计时器
1)简单实现
import React, { useEffect, useState } from "react";
const List = () => {
const [count,setCount] = useState(0);
useEffect(()=>{
const timeRef = setInterval(()=>{
setCount((count) => count + 1);
},1000)
return ()=>{
clearInterval(timeRef);
}
},[]);
return (
<div>{count}</div>
);
};
export default List;
2)封装 hook(支持自定义初始值和时间间隔)
// 使用
const {count} = useInterval(0,1000);
// 封装hook
const useInterval = (initValue: number,delay:number) => {
const [count, setCount] = useState(initValue);
useEffect(() => {
const timer = setInterval(()=>{
setCount(count => count + 1)
}, delay);
return () => {
clearInterval(timer);
};
}, []);
return {count}
};
3)封装 hook(改变当前组件内状态)
// 使用setCount(count => count + 1)
useInterval(()=> setCount(count => count + 1),1000);
// 封装hook
const useInterval = (callback: ()=> void,delay:number) => {
useEffect(()=>{
let timer = setInterval(callback,delay);
return ()=>{
clearInterval(timer);
}
},[]);
};
// 使用setCount(count + 1)
useInterval(()=> setCount(count + 1),1000);
// 封装 hook
const useInterval = (callback: () => void, delay: number) => {
useEffect(() => {
const time = setInterval(callback, delay);
return () => {
clearInterval(time);
};
});
};
React Hook使用时必须显示指明依赖,不能在条件语句中声明Hook
3. 封装Button组件
Button调用方式如下所示:
<Button
classNames='btn1 btn2'
onClick={()=>alret(1)}
size='middle'
>按钮文案</Button>
封装一个Button组件如下:
const Button: React.FC = memo((props:any) => {
const { classNames, onClick, size } = props;
const sizeList = ['small','large','middle'];
const getClassName = ()=>{
if(size && sizeList.includes(size)){
return `btn-${size} ${classNames}`;
}
return classNames;
}
const handleClick = ()=>{
if(onClick){
onClick();
}
}
return (
<div
className={getClassName()}
onClick={handleClick}
>
{props.children}
</div>
);
});
.btn-small{
width: 32px;
height:24px;
}
.btn-middle{
width: 50px;
height:32px;
}
.btn-large{
width: 88px;
height:42px;
}
原文链接:https://juejin.cn/post/7343862045123035188 作者:喝咖啡的女孩