
什么是 Vapor mode
Vapor mode 中文直译是 蒸汽模式
这是从 Vapor 的 github 仓库中截的一段描述


为了开发 Vapor mode,vue团队从 vue3 的主线分支 fork 出了一个新的仓库「core-vapor」,目标是为了实现 vue 的 无虚拟DOM 渲染模式
这里对 Vue 发展过程比较了解的同学可能就会发问了,**「Vue1.0」不就是无虚拟DOM的版本吗,发展了这么多年怎么还往回走呢?说到这里我们就不得不梳理一下 Vue 各个大版本的「架构演进史」**了
Vue 1.0 量子纠缠式的细粒度绑定
这是 Vue 初具雏形的一个里程碑,此时还没有完备的 响应式 系统,这个时期大家谈论得最多的是基于 数据劫持 + 依赖收集 的响应式实现方案,以及实现细节中的 Watcher 与 Dep 两兄弟
没有了解过的同学可以看一下这张「渲染流程图」,能帮助你快速建立起对 Vue1.0 版本的认知
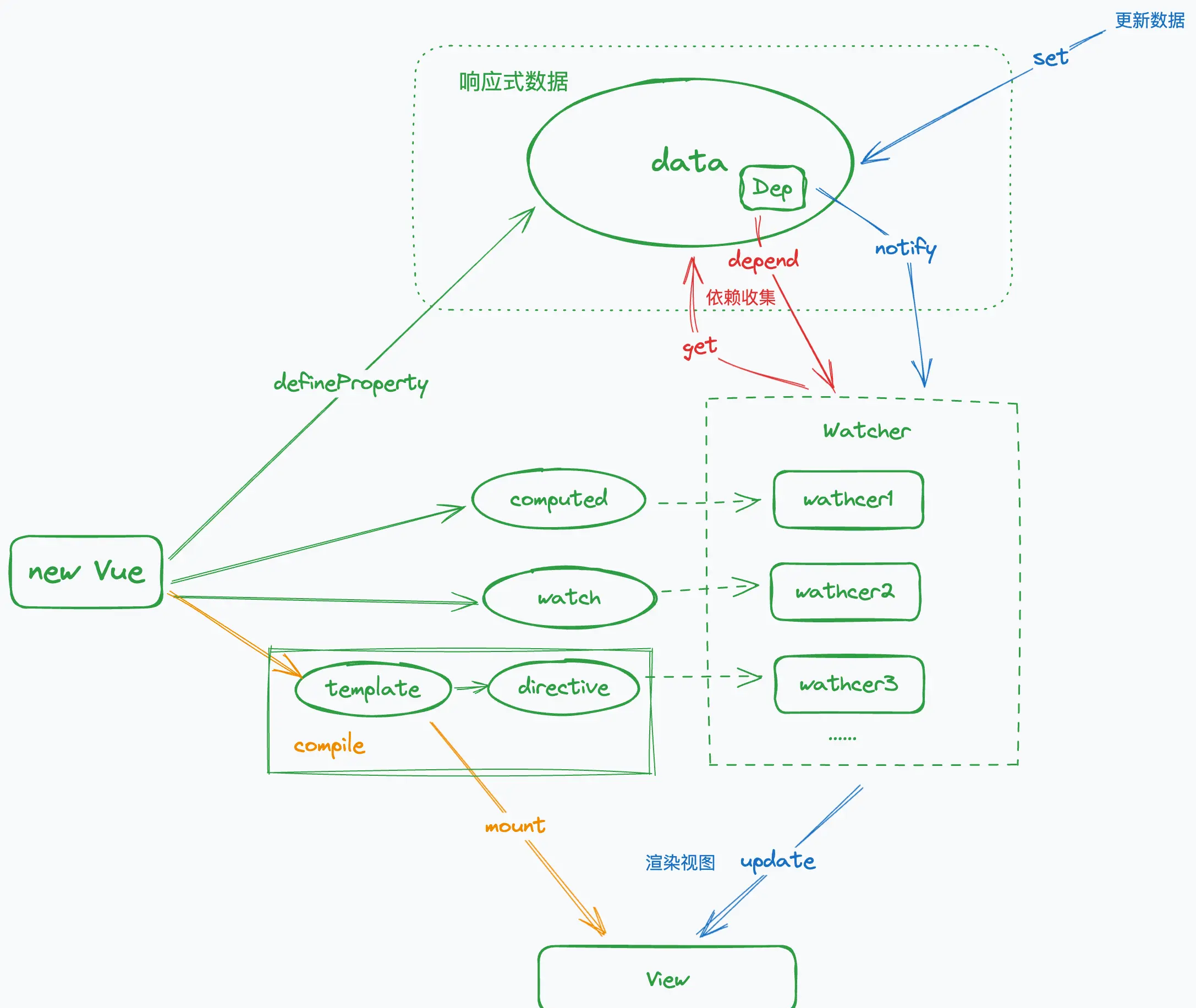
在还没有 SFC(单文件组件)之前,Vue 可以说是一个实打实的**「运行时」** 框架,上图简要体现了当我们 new Vue({…}) 之后,发生的一系列过程
-
用 defineProperty 实现数据劫持,目的是代理数据,拦截所有对数据的 get 和 set 操作,这个过程也被称为「getter/setter」化
-
属性的「getter」的主要作用是收集依赖。这里的「依赖」是指所有访问该属性的逻辑,可能是一个「计算属性」,可能是一个「监听器」,也可能是模版中的「指令」或者「插值表达式」。在实现层面,这些不同的依赖都被抽象为了一个统一的概念 —— Watcher,会被存储在每个属性的 Dep 实例中
-
属性的「setter」则是当数据被修改后,通知 Dep 中收集的 Watcher 去更新视图
在整个流程中,Vue 依赖收集的**「粒度」是很细的,只要是访问了「响应式」数据的地方,都会被作为「依赖」**给收集起来
往上层说,也就是**「数据」与对应的「UI」形成了绑定关系,这也是让 Vue 在「更新视图」时有着极高的效率的根本原因。这种绑定关系就像量子纠缠一样,「数据」变化的同时「UI」**就能收到通知从而做出更新
但任何事物都有两面性,过细的依赖收集是优势也是短板,随着项目体量的增长,运行时会产生越来越多的 Watcher 和 Dep,导致占用过多的内存,进而影响页面的性能。
如果一个方案只能支撑小体量的项目有良好的**「性能」**表现,显然不是「最优解」
Vue 2.0 调整依赖收集粒度,引入虚拟DOM
为了在大型项目上有更好的性能表现,Vue2.0版本做出了很大的调整。从下面的流程图中,我们不难发现 Vue 的架构体系有了直观的变化
- 相比 1.0 版本,出现了组件的概念
- 将依赖收集的粒度调整为「组件级别」,即一个组件就是一个 Watcher
- 引入了 虚拟DOM 并且成为了渲染流程中非常重要的一环
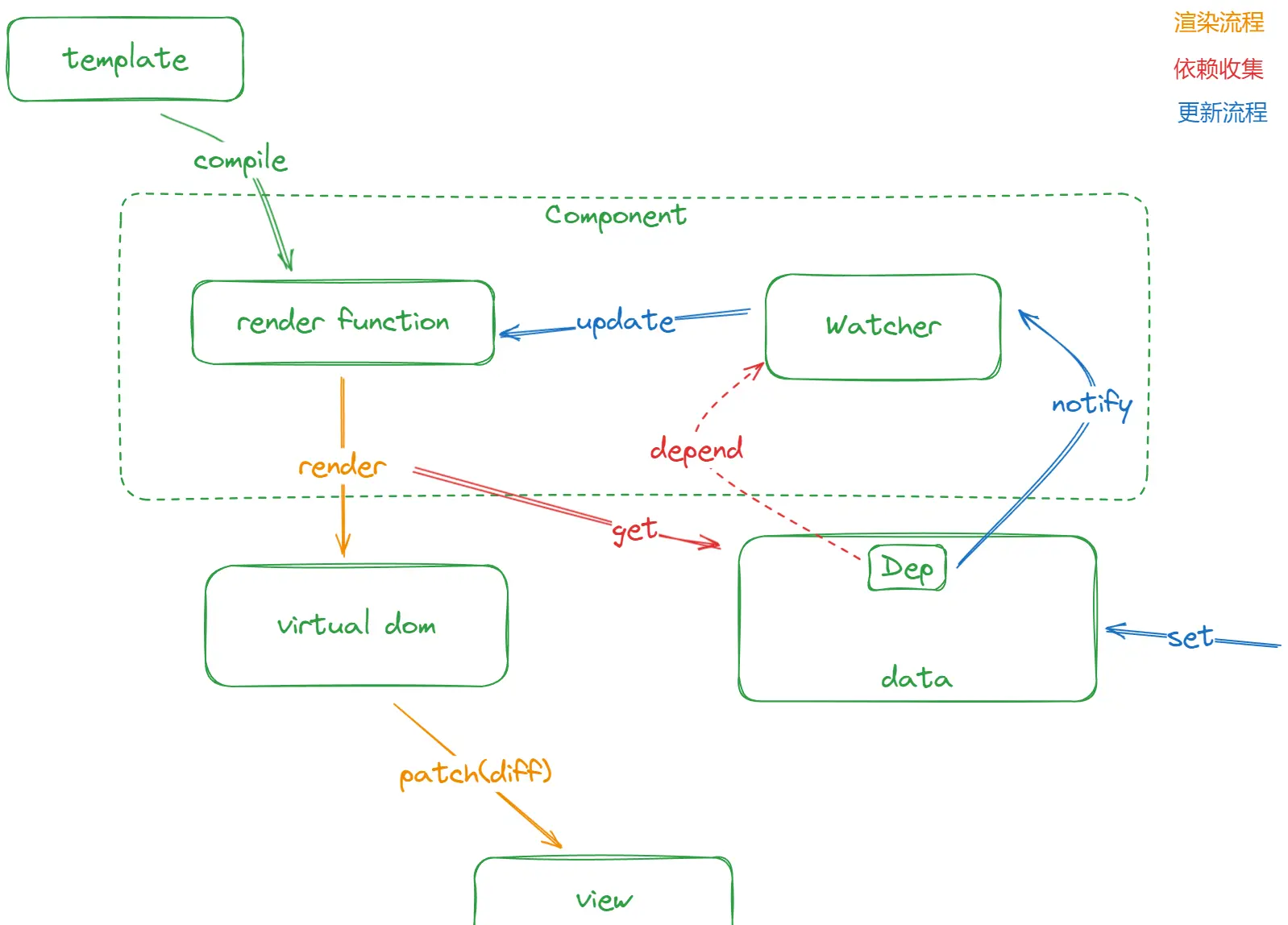
整体上来看,「响应式」数据不再关注组件内部的「依赖」,当数据被修改后只通知到组件,组件再通过 diff 算法找出「虚拟DOM」中变化部分,将这部分更新到「真实DOM」上。这本质上是 时间换空间 的权衡,通过适当降低**「运行时」的「更新效率」来换取更少的「内存开销」**
同时期 Vue 也新增了 SFC(.vue文件),由于 .vue 文件是框架提供的“魔法”,并不能直接交给浏览器去执行,因此就需要一个能打破“魔法”的工具,将 .vue 转换为 .js,这个工具的核心就是 编译器(compiler),打破魔法的过程则被称为 编译(compile),也就是说经过编译后,我们在 .vue 文件中写的 v-if, v-for, 插值表达式 等等特性都会变成普通的 javascript 逻辑。template 也就是在这个阶段被转换为了 render 函数
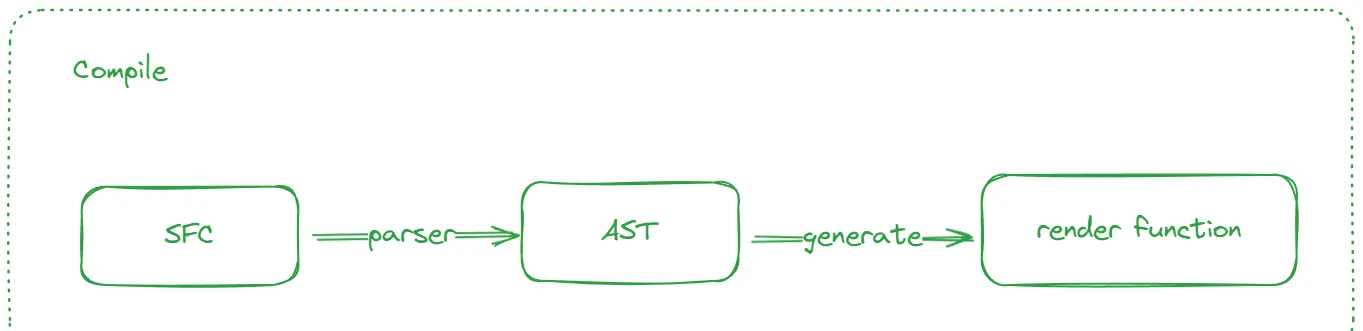
虽然 1.0 版本中也存在 compile 过程,但做的事儿却发生了很大的变化
| compile | 1.0 | 2.0 |
|---|---|---|
| 阶段 | 运行时 | 编译时 |
| 作用 | 将模板中的指令,插值等解析为对应的逻辑并执行 | 将模板解析为抽象语法树(AST),生成渲染函数 |
通过简单的对比我们不难发现,尽管编译的执行阶段完全不同了,对模板的解析还是主旋律
其实到这里,是不是感觉 Vue 已经从架构上做到了极致的优化?不要着急,我们看完 Vue 3.0 版本的演进后再下论断
Vue 3.0 组合式API
随着 typescript 在前端的兴起,以及代表着 元编程 能力的 proxy 被各大主流浏览器所支持,Vue3 以被完全重构的姿态登场了
同时,为了解决 选项式API 逻辑太分散,开发者难以优雅的写出高内聚的代码 这一痛点,在得到 React hooks 思想的启发后,Vue3 也推出了 组合式API,虽然期间也有 mixin 之类的方案,但或多或少都有弊端
而在 组合式API 模式下,利用 hooks 能够很好的组合业务功能,实现逻辑内聚
除了新特性之外,在细节的打磨上,Vue也做了很多优化,比如
- 预字符串化
- 静态节点提升
- patch flag
细心的同学应该已经发现了,这些优化都是属于 编译时 优化,而不是 运行时 优化,因为在运行时,可优化的方向实在不多,基本是围绕 patch 过程的 diff 算法来进行的
再说 Vue vapor
在回顾了 Vue 的迭代过程后,我们就可以回到主题 Vapor mode 了,这也是 Vue 围绕 编译时优化 进行的一项研究,当然也是受到了 SolidJS 的启发
前面我们提到,基于的 Vue 的架构体系,运行时优化 几乎只能围绕如何更快的找出 虚拟DOM 中变化的部分来做
如果回到 Vue1.0 没有虚拟DOM的形态,那个时候的细粒度绑定就不需要去找变化,更不需要虚拟DOM,但痛点是
-
依赖是在运行时确定的。系统初始化需要在编译阶段解析指令等并收集依赖,会增加首屏渲染的时间 -
细粒度的依赖收集导致产生大量的 Watcher,带来更多的内存开销
现在我们换一个视角,如果把依赖的确定时机从运行时挪到编译时,通过编译手段将每个 响应式数据 变化时需要执行的更新逻辑生成出来,不就能解决上述的第一个痛点了吗,这也就是 Vapor mode 的思路
至于第二个痛点,从理论上来说,依赖收集的粒度由粗到细,势必会增加内存开销,这个点 Vapor mode 将如何处理?我们存疑,等它正式发布后再 callback
那么本期就到这里~ 我们下期再分享更多干货
觉得还不错的友友帮忙点点赞和在看哦
原文链接:https://juejin.cn/post/7348464590160707636 作者:木木剑光