

大文件分片上传实战与优化(前端Part)
1. 需求分析
1.1 分析
实现大文件上传, 其中包括以下功能
秒传: 文件已存在, 直接给前端返回文件 url
- 记录文件的 hash 与元数据到数据库中
- 上传文件前先计算 hash 和获取文件元数据请求接口进行比对
- 若比对成功则说明文件已存在, 直接返回前端文件 url
断点续传: 上传过程意外中断, 下次上传时不需要从头上传整个文件
- 前端将文件分片上传, 后端接收分片然后进行合并
- 上传分片前先请求接口查询需要上传的分片即实现断点续传
1.2 优化与亮点
- 实现了基于文件真实上传进度的进度条
- 实现了可控制 Promise 并发数量的 PromisePool
- 实现了基于 WebWorker 的 WorkerPool / ThreadPool
- 解决了前端计算大文件 hash 速度过慢的痛点, 最终实现 5GB 文件计算 Hash 仅需 3.5 秒
- 解决了 Node 中合并文件分片导致文件损坏的问题 (思路: 在 Minio 中做合并而不是在 Node 里合并) (详见后续文章)
1.3 技术选型
具体使用什么技术栈并不重要, 如果你使用的是 Vue/React 同样适用
前端: Angular + NG-Zorro
后端: Nest.js + Prisma + MySQL + Minio(文件存储)
(OOP 的大胜利)
2. 实现文件切片
2.1 目标
就是将文件按指定的切片大小进行切片, 最终拿到文件的 ArrayBuffer 数组用于上传和分片 Hash 计算
2.2 实现
传入文件然后返回文件切片后的 Blob 数组, 不过 Blob 数组不能直接用于计算分片 hash, 还需要将它们转成 ArrayBuffer 数组
/**
* 分割文件
* @param file
* @param baseSize 默认分块大小为 1MB
* @private
*/
function sliceFile(file: File, baseSize = 1): Blob[] {
const chunkSize = baseSize * 1024 * 1024 // KB
const chunks: Blob[] = []
let startPos = 0
while (startPos < file.size) {
chunks.push(file.slice(startPos, startPos + chunkSize))
startPos += chunkSize
}
return chunks
}
可以使用 FileReader 转换, 可以直接转换, 二者没有性能差距
区别只是 FileReader API 的兼容性可能会更好一点
以下两种实现二选一即可
/**
* 将 File 转成 ArrayBuffer
* 注意: Blob 无法直接移交到 Worker 中, 所以需要放到主线程中执行
* @param chunks
* @private
*/
async function getArrayBufFromBlobs(chunks: Blob[]): Promise<ArrayBuffer[]> {
async function readAsArrayBuffer(file: Blob) {
return new Promise<ArrayBuffer>((rs) => {
const fileReader = new FileReader()
fileReader.onload = (e) => rs(e.target!.result as ArrayBuffer)
fileReader.readAsArrayBuffer(file)
})
}
return await Promise.all(chunks.map((chunk: Blob) => readAsArrayBuffer(chunk)))
}
/**
* 功能同上但语法更简洁
* @param chunks
*/
async function getArrayBufFromBlobsV2(chunks: Blob[]): Promise<ArrayBuffer[]> {
return Promise.all(chunks.map(chunk => chunk.arrayBuffer()))
}
至此已实现了前端文件切片
2.3 踩坑
有些文章将可以把切片过程放到 WebWorker 中, 以避免阻塞主线程
实际情况是:
切片过程不会消耗太久时间, 其中主要是 IO 瓶颈
而 Blob[] 转 ArrayBuffer[] 的过程是基于 Promise 的, 这并不会阻塞主线程
注意 ! ! !
-
如果你将这个过程放到 Worker 中, 由于 File 或 Blob 并不是 Worker 中的可 Transfer 对象
-
此处会导致 主线程与 Worker 通信时进行结构化克隆, 由此会产生额外的CPU性能消耗和内存消耗
-
而且如果文件很大时(大概超过2GB)会导致 Worker 线程 OOM (内存溢出错误)
3. 前端计算分片 Hash
3.1 目标
使用文件分片的 Hash 来标识文件分片, 用来判断这个分片是否已经上传过了
3.2 存在的问题与解决思路
计算文件分片 Hash 是一个 CPU 密集型任务, 直接在主线程中计算 hash 必定会导致 UI 卡死, 考虑放到 WebWorker 中计算 Hash
ArrayBuffer 是可 Transfer 的对象, 在主线程与 Worker 线程通信时, 可以通过移交控制权的方式通信, 避免线程通信引起的结构化克隆
分片之间的 Hash 计算没有关联, 而 WebWorker 可以用来开额外的计算线程, 考虑基于 WebWorker 实现线程池(WorkerPool)来加速计算分片 Hash
当文件较大时计算使用分片的 MD5值作为 Hash 计算速度仍然较慢, 但分片的 hash 其实只是为了标识分片, 对于唯一性要求并不高, 考虑在文件较大的场景下使用 CRC32 值作为分片的 Hash
CRC32的十六进制表示只有8位(MD5有32位), 且 CPU 对计算 CRC32 有硬件加速, 速度会比计算 MD5 快得多
3.3 Web Worker
用于计算 MD5 的 Worker
这里使用了 SparkMD5 计算文件的 MD5
// md5.worker.ts
/// <reference lib="webworker" />
import { WorkerMessage } from './util/worker-message'
import { WorkerLabelsEnum } from './types/worker-labels.enum'
import SparkMD5 from 'spark-md5'
addEventListener('message', ({ data }: { data: ArrayBuffer }) => {
const hash = SparkMD5.ArrayBuffer.hash(data)
postMessage(
new WorkerMessage(WorkerLabelsEnum.DONE, {
result: hash,
chunk: data,
}),
[data], // 用于 transfer 的数据, 以避免结构化克隆
)
})
用于计算 CRC32 的 Worker
// crc32.worker.ts
/// <reference lib="webworker" />
import { getCrc, getCrcHex } from '../utils/upload-helper'
import { WorkerMessage } from './util/worker-message'
import { WorkerLabelsEnum } from './types/worker-labels.enum'
addEventListener('message', ({ data }: { data: ArrayBuffer }) => {
const crc = getCrc(data)
const hash = getCrcHex(crc)
postMessage(
new WorkerMessage(WorkerLabelsEnum.DONE, {
result: hash,
chunk: data,
}),
[data], // 用于 transfer 的数据, 以避免结构化克隆
)
})
WorkerMessage: 用于 Worker 线程向主线程通信
// WorkerMessage.ts
import { WorkerLabelsEnum } from '../types/worker-labels.enum'
export class WorkerMessage<T = any> {
label: WorkerLabelsEnum
content?: T
constructor(label: WorkerLabelsEnum, content?: T) {
this.label = label
this.content = content
}
}
WorkerLabelsEnum: 用于标识 Worker Message 的类型
// WorkerLabelsEnum.ts
export enum WorkerLabelsEnum {
INIT,
CHUNK,
DONE,
}
WorkerRep: WorkerMessage 的进一步封装, 方便传泛型
// WorkerRep.ts
export interface WorkerRep<T = any> {
data: WorkerMessage<T>
}
3.4 Worker Pool 的实现
使用 Worker Pool 来复用 Worker 而不是每次计算 hash 都开新的 Worker
WorkerWrapper: 基于 Promise 追踪当前 Worker 的运行状态
import { WorkerRep } from './worker-message'
import { WorkerLabelsEnum } from '../types/worker-labels.enum'
export enum StatusEnum {
RUNNING = 'running',
WAITING = 'waiting',
}
export class WorkerWrapper {
worker: Worker
status: StatusEnum
constructor(
worker: Worker,
) {
this.worker = worker
this.status = StatusEnum.WAITING
}
run<T>(param: ArrayBuffer, params: ArrayBuffer[], index: number) {
this.status = StatusEnum.RUNNING
return new Promise<T>((rs, rj) => {
this.worker.onmessage = ({ data }: WorkerRep<{ result: string; chunk: ArrayBuffer }>) => {
const { label, content } = data
if (label === WorkerLabelsEnum.DONE && content) {
params[index] = content.chunk // 归还分片的所有权
this.status = StatusEnum.WAITING
rs(content.result as T)
}
}
this.worker.onerror = (e) => {
this.status = StatusEnum.WAITING
rj(e)
}
this.worker.postMessage(param, [param]) // 用于 transfer 的数据, 以避免结构化克隆
})
}
}
WorkerPool: 用于管理 WorkerWrapper, 实现 Worker 复用
核心思路是使用发布订阅模式来订阅当前 正在跑的 Worker 的数量(curRunningCount)
此处使用了 Rxjs 中的 BehaviorSubject, 也可以自己写一个 发布订阅模式来实现
只需要实现两个方法 subscribe() 和 next(), 其中 subscribe 用来订阅, next 用于发布新值
import { StatusEnum, WorkerWrapper } from './worker-wrapper'
import { BehaviorSubject } from 'rxjs'
export abstract class WorkerPool {
pool: WorkerWrapper[] = []
maxWorkerCount: number
curRunningCount = new BehaviorSubject(0)
results: any[] = []
protected constructor(
maxWorkers = navigator.hardwareConcurrency || 4,
) {
this.maxWorkerCount = maxWorkers
}
exec<T>(params: ArrayBuffer[]) {
const workerParams = params.map(
(param, index) => ({ data: param, index }),
)
return new Promise<T[]>((rs) => {
this.curRunningCount.subscribe(count => {
if (count < this.maxWorkerCount && workerParams.length !== 0) {
// 当前能跑的任务数量
let curTaskCount = this.maxWorkerCount - count
if (curTaskCount > params.length) {
curTaskCount = params.length
}
// 此时可以用来执行任务的 Worker
const canUseWorker: WorkerWrapper[] = []
for (const worker of this.pool) {
if (worker.status === StatusEnum.WAITING) {
canUseWorker.push(worker)
if (canUseWorker.length === curTaskCount) {
break
}
}
}
const paramsToRun = workerParams.splice(0, curTaskCount)
// 更新当前正在跑起来的 worker 数量
this.curRunningCount.next(this.curRunningCount.value + curTaskCount)
canUseWorker.forEach((workerApp, index) => {
const param = paramsToRun[index]
workerApp.run(param.data, params, param.index)
.then((res) => {
this.results[param.index] = res
})
.catch((e) => {
this.results[param.index] = e
})
.finally(() => {
this.curRunningCount.next(this.curRunningCount.value - 1)
})
})
}
if (this.curRunningCount.value === 0 && workerParams.length === 0) {
rs(this.results as T[])
}
})
})
}
}
WorkerPoolForMd5s: 用于实现使用 Worker Pool 计算所有分片的 MD5 值
import { WorkerWrapper } from './util/worker-wrapper'
import { WorkerPool } from './util/worker-pool'
export class WorkerPoolForMd5s extends WorkerPool {
constructor(maxWorkers: number) {
super(maxWorkers)
this.pool = Array.from({ length: this.maxWorkerCount }).map(
() =>
new WorkerWrapper(
new Worker(new URL('./md5-single.worker', import.meta.url)),
),
)
}
}
WorkerPoolForCrc32s: 用于实现使用 Worker Pool 计算所有分片的 CRC32 值
import { WorkerPool } from './util/worker-pool'
import { WorkerWrapper } from './util/worker-wrapper'
export class WorkerPoolForCrc32s extends WorkerPool {
constructor(
maxWorkers = navigator.hardwareConcurrency || 4,
) {
super(maxWorkers)
this.pool = Array.from({ length: this.maxWorkerCount }).map(
() =>
new WorkerWrapper(
new Worker(new URL('./crc32-single.worker', import.meta.url)),
),
)
}
}
3.5 使用 Worker Pool 计算分片的 hash 值
export class WorkerService {
readonly MAX_WORKERS = 8
md5SingleWorkerPool: WorkerPoolForMd5s | undefined
crc32SingleWorkerPool: WorkerPoolForCrc32s | undefined
// 计算所有分片的 MD5
getMD5ForFiles(chunks: ArrayBuffer[]): stirng[] {
if (this.md5SingleWorkerPool === undefined) {
this.md5SingleWorkerPool = new WorkerPoolForMd5s(this.MAX_WORKERS)
}
return this.md5SingleWorkerPool.exec<string>(chunks)
}
// 计算所有分片的 CRC32
getCRC32ForFiles(chunks: ArrayBuffer[]): stirng[] {
if (this.crc32SingleWorkerPool === undefined) {
this.crc32SingleWorkerPool = new WorkerPoolForCrc32s(this.MAX_WORKERS)
}
return this.crc32SingleWorkerPool.exec<string>(chunks)
}
}
3.6 踩坑
-
这里如果将
new Worker(new URL('./crc32-single.worker', import.meta.url)中的 url 拆出来作为一个变量传进去会导致在运行时浏览器无法正确拿到 Worker 文件, 具体原因未知, 可能是打包工具引起的问题 -
确保 WorkerPoolForMd5s 和 WorkerPoolForCrc32s 是单例的, 否则会导致浏览器创建过多的 Web Worker
-
Worker 是需要手动关闭的, 可以找到合适的时机去关掉所有的 Worker
3.7 性能实测
硬件情况: Ryzen9 5900HX + 32Gb DDR4
3种方式各算了两次
计算 1.8GB 文件分片的 MD5
[主线程中直接算(单线程)]
14585.115966796875 ms
14066.404052734375 ms
8线程 WebWorker => 比单线程快了 670%
2174.992919921875 ms
2169.323974609375 ms
12线程 WebWorker => 比 8 单线程快了 19%, 比单线程快了 776%
1825.158935546875 ms
1878.386962890625 ms
总结: 使用多线程的方式可以使 hash 计算性能提高 6 ~ 7 倍
4. 前端计算文件 Hash
4.1 目标
计算文件的 Hash 用来标识这个文件是否已经上传过了
4.2 存在的问题与解决思路
计算全部文件的 hash 无法采用并行计算的方式, 实测假定用户上传 1.8GB 文件, 仅算文件 MD5 就要消耗 15秒 时间(不包括计算文件分片 hash 的时间)
考虑
- 使用 wasm
- 使用 MerkleTree(默克尔树) 的树根 hash 作为 文件的 hash (本文采用)
4.3 MerkleTree
每个叶子节点是对应数据分片的 Hash, 非叶子结点为它 2 个子节点的哈希, 从叶子结点层层向上计算 hash, 即得到 默克尔树根, 它可以用来校验数据集的完整性
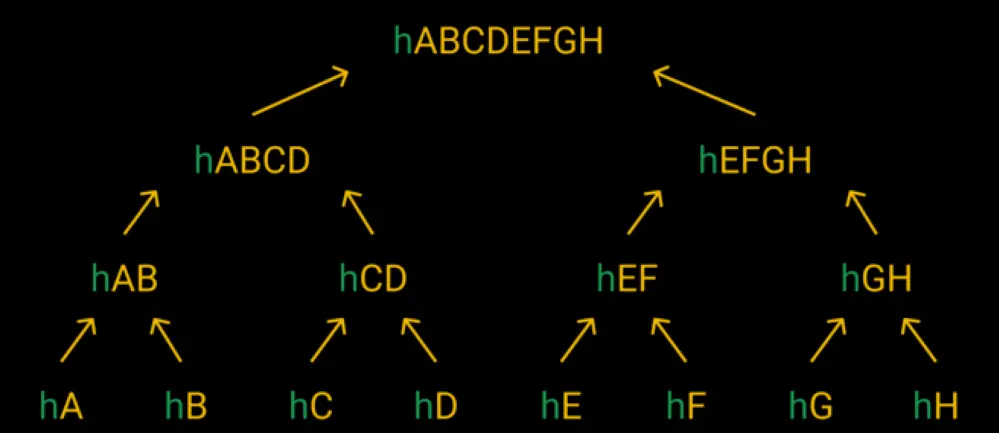

如图所示, 其中的
hA hB hC hD hE hF hG hH 即为各个文件分片的 Hash
hAB 只是基于文件分片的 Hash 计算 Hash
所以得到默克尔树根的 hash 速度会非常快, 因为并没有直接计算全部文件的 hash, 只是根据全部分片的 hash 进行计算
最后使用 树根的 hash 作为 文件 hash, 这样即实现了标识文件的唯一, 计算速度又非常快
4.4 MerkleTree 的实现
此处仍然使用 SparkMD5 来计算 MD5 作为 hash
这里实现了 MerkleTree 的序列化和反序列化方法, 如果想保存整个 MerkleTree 树可以将这个序列化后的结果存入数据库, 我在这里只是用到了计算 MerkleTree 的树根
import SparkMD5 from 'spark-md5'
// 定义 Merkle 树节点的接口
interface IMerkleNode {
h: string
l: IMerkleNode | null
r: IMerkleNode | null
}
// 定义 Merkle 树的接口
interface IMerkleTree {
root: IMerkleNode
leafs: IMerkleNode[]
// 你可以根据需要添加其他属性或方法,例如校验、添加和生成树等功能
}
// Merkle 树节点的类实现
class MerkleNode implements IMerkleNode {
h: string
l: IMerkleNode | null
r: IMerkleNode | null
constructor(hash: string, left: IMerkleNode | null = null, right: IMerkleNode | null = null) {
this.h = hash
this.l = left
this.r = right
}
}
// Merkle 树的类实现
export class MerkleTree implements IMerkleTree {
root: IMerkleNode
leafs: IMerkleNode[]
constructor(hashList: string[])
constructor(leafNodes: IMerkleNode[])
constructor(nodes: string[] | IMerkleNode[]) {
if (nodes.length === 0) {
throw new Error('Empty Nodes')
}
if (typeof nodes[0] === 'string') {
this.leafs = nodes.map((node) => new MerkleNode(node as string))
} else {
this.leafs = nodes as IMerkleNode[]
}
this.root = this.buildTree()
}
getRootHash() {
return this.root.h
}
buildTree(): IMerkleNode {
// 实现构建 Merkle 树的逻辑。根据叶子节点创建父节点,一直到根节点。
let currentLevelNodes = this.leafs
while (currentLevelNodes.length > 1) {
const parentNodes: IMerkleNode[] = []
for (let i = 0; i < currentLevelNodes.length; i += 2) {
const left = currentLevelNodes[i]
const right = i + 1 < currentLevelNodes.length ? currentLevelNodes[i + 1] : null
// 具体的哈希计算方法
const parentHash = this.calculateHash(left, right)
parentNodes.push(new MerkleNode(parentHash, left, right))
}
currentLevelNodes = parentNodes
}
return currentLevelNodes[0] // 返回根节点
}
// 序列化 Merkle 树
serialize(): string {
const serializeNode = (node: IMerkleNode | null): any => {
if (node === null) {
return null
}
return {
h: node.h,
l: serializeNode(node.l),
r: serializeNode(node.r),
}
}
const serializedRoot = serializeNode(this.root)
return JSON.stringify(serializedRoot)
}
// 反序列化 Merkle 树
static deserialize(serializedTree: string): MerkleTree {
const parsedData = JSON.parse(serializedTree)
const deserializeNode = (data: any): IMerkleNode | null => {
if (data === null) {
return null
}
return new MerkleNode(data.h, deserializeNode(data.l), deserializeNode(data.r))
}
const root = deserializeNode(parsedData)
if (!root) {
throw new Error('Invalid serialized tree data')
}
// 创建一个包含所有叶子节点的数组,这是为了与 MerkleTree 的构造函数兼容
// 没有保存这些叶子节点的序列化版本,所以这里需要一些额外的逻辑来处理
// 如果你需要将整个树的所有节点存储为序列化版本,那么可能需要修改这部分逻辑
const extractLeafNodes = (node: IMerkleNode): IMerkleNode[] => {
if (node.l === null && node.r === null) {
return [node]
}
return [
...(node.l ? extractLeafNodes(node.l) : []),
...(node.r ? extractLeafNodes(node.r) : []),
]
}
const leafNodes = extractLeafNodes(root)
return new MerkleTree(leafNodes)
}
private calculateHash(left: IMerkleNode, right: IMerkleNode | null): string {
return right ? SparkMD5.hash(left.h + right.h) : left.h
}
}
4.5 使用 MerkleTree 树根的 Hash 作为文件 Hash
// chunksHash 为所有文件分片的 hash 数组
const merkleTree = new MerkleTree(chunksHash)
const fileHash = merkleTree.getRootHash()
5. 文件分片的并发上传
5.1 目标
多个文件分片可以同时上传到后端, 但不能使用 Promise.all() 直接将所有分片一起传到后端,
当文件分片数量较多时, 会导致同时开启的 HTTP 链接过多
使用一个 PromisePool 来控制同时处于 pending 状态的 Promise 的数量
注意:
使用 Promise.all() 只是用来收集 Promise 数组的执行结果, 它并不能用来控制同时处于 Pending 状态 Promise 的数量, 而 Promise 一旦创建了就会立即执行其中 new Promise() 中的同步代码(即发送网络请求),
所以需要创建 Promise 这个过程用函数包起来, 以实现当需要的时候再去执行
即函数调用的时候才会创建这个 Promise
5.2 实现
实现思路同 Worker Pool
接收一个 () => Promise<any> 数组作为任务
import { BehaviorSubject } from 'rxjs'
type AsyncFunction = () => Promise<any>
export class PromisePool {
private readonly queue: { fn: AsyncFunction, index: number }[] = []
private readonly maxConcurrentTasks: number
private results: any[] = []
curRunningCount = new BehaviorSubject(0)
constructor(
functions: AsyncFunction[],
maxConcurrentTasks: number = navigator.hardwareConcurrency || 8,
) {
this.queue = functions.map((fn, index) => ({ fn, index }))
this.maxConcurrentTasks = maxConcurrentTasks
}
exec<T>() {
return new Promise<T[]>((rs) => {
this.curRunningCount.subscribe((count) => {
if (count < this.maxConcurrentTasks && this.queue.length !== 0) {
// 当前需要跑的任务数量
let curTaskCount = this.maxConcurrentTasks - count
if (curTaskCount > this.queue.length) {
curTaskCount = this.queue.length
}
// 当前要跑的任务
const tasks = this.queue.splice(0, curTaskCount)
this.curRunningCount.next(this.curRunningCount.value + curTaskCount)
// 执行任务
tasks.forEach((taskWrap) => {
const { fn, index } = taskWrap
fn().then((result) => {
this.results[index] = result
}).catch((error) => {
this.results[index] = error
}).finally(() =>
this.curRunningCount.next(this.curRunningCount.value - 1)
)
})
}
if (this.curRunningCount.value === 0 && this.queue.length === 0) {
rs(this.results as T[])
}
})
})
}
}
5.3 使用示例
可以看见同时处于 跑起来了状态的 Promise 只有 4 个
async testPromisePool() {
const arr = [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ]
const asyncFns = arr.map(
(num) => async () => {
await new Promise<number>((rs) => {
console.log('跑起来了: ' + num)
setTimeout(() => {
rs(num * 2)
}, 100)
})
return new Promise((rs) => {
setTimeout(() => {
rs('结果: ' + num * 10)
}, 2000)
})
},
)
const pool = new PromisePool(asyncFns, 4)
pool.exec().then((res) => {
console.log(res)
})
}
6. 基于实际上传进度的进度计算
6.1 思路 (Axios)
使用可以设置其中的上传参数: onUploadProgress, 用于处理上传进度事件, 详见 axios-http.com/zh/docs/req…
6.2 思路 (Angular HTTP Client)
通过 Rxjs 的 pipe() 来处理上传事件, 详见 angular.cn/guide/http#…
6.3 基于 HTTP Client 的实现
封装 HttpClient, 其中 cb(event.loaded) 中的 event.loaded 即为当前请求已经上传了多少数据
// http.service.ts
import { HttpClient, HttpEvent, HttpEventType, HttpRequest } from '@angular/common/http'
import { BehaviorSubject, last, lastValueFrom, map, Observable } from 'rxjs'
export class HttpService {
constructor(private http: HttpClient) {}
private getEventMessage(event: HttpEvent<any>, cb?: (current: any) => void) {
if (event.type === HttpEventType.UploadProgress) {
cb && cb(event.loaded)
}
}
postPWithProgress<T>(
url: string,
body: any,
extra: HttpExtraParam = {},
cb?: (current: number) => void,
) {
const urlWithExtra = appendQueryParams(url, extra)
return lastValueFrom(
this.http
.request<T>(
new HttpRequest('POST', urlWithExtra, body, {
reportProgress: true,
}),
)
.pipe(
map((event) => this.getEventMessage(event, cb)),
last(),
),
)
}
}
完整应用详见 前端上传流程
7. 前端上传流程与策略
7.1 流程
- 获取文件元数据
- 文件分片
- 计算分片 Hash 与 文件 Hash
- 检查文件是否已经上传过
- 查询需要上传的文件分片
- 构建上传参数
- 上传实际需要上传的分片
- 待全部分片上传完成后校验分片
- 合并分片
7.2 策略
文件分片大小设定为 10MB 一个分片
Hash 策略
- 当文件分片数量 为1片时 (10MB 以下) 直接计算整个文件的 MD5
- 当文件分片数量小于 100 片时(1GB 以下) 基于分片的 MD5 计算 默克尔树根作为 文件 Hash
- 当文件分片数量大于 100 片时(1GB 以上) 基于分片的 CRC32 Hex 计算 默克尔树根作为 文件 Hash
7.3 实时上传进度的思路
其实类似于多线程状态下去刷一个数据(已上传数据的大小)
-
使用一个数组去存放所有请求的已上传文件大小, 初始值全是 0
-
按数组顺序刷写整个数组中各个请求的上传进度, 最后将数组中各元素求和, 即得到当前总的已上传大小
-
使用一个 定时器每隔 100ms 读一下当前上传的进度, 更新进度条即可
-
并不需要每个子上传进度上传时就更新进度条, 类似节流的思想
详见整体实现部分的代码
7.4 整体实现
interface IMetaData {
size: number,
lastModified: number,
type: string
}
export class MinioUploaderService {
// 用于追踪当前的上传阶段
uploadStatus = new BehaviorSubject<string>('Please select a file.')
constructor(private uploadApiSvc: UploadApiService) {}
async doUpload(
file: File,
chunkSize: number,
cb: (progress: number) => void,
) {
// 分片数量小于 borderCount 用 MD5, 否则用 CRC32 算 Hash
const BORDER_COUNT = 100
// 文件大小
const fileSize = file.size / 1000
// 文件元数据
const metadata: IMetaData = {
size: file.size,
lastModified: file.lastModified,
type: file.type,
}
// 文件分片
this.uploadStatus.next('Parsing file ...')
const chunksBlob = sliceFile(file, chunkSize)
const chunksBuf = await getArrayBufFromBlobsV2(chunksBlob)
// 按文件分片数量执行不同 Hash 策略
let chunksHash: string[] = []
if (chunksBuf.length === 1) {
chunksHash = [getMD5FromArrayBuffer(chunksBuf[0])]
} else if (chunksBuf.length <= BORDER_COUNT) {
chunksHash = await this.workerSvc.getMD5ForFiles(chunksBuf)
} else {
chunksHash = await this.workerSvc.getCRC32ForFiles(chunksBuf)
}
const merkleTree = new MerkleTree(chunksHash)
const fileHash = merkleTree.getRootHash()
// 检查文件是否已经上传过
this.uploadStatus.next('Checking file if exist ...')
const { data: existUrl } = await this.uploadApiSvc.checkFileIfExist(fileHash, fileSize)
if (existUrl) {
this.uploadStatus.next('Completed.')
return existUrl
}
// 查询需要上传的分片
this.uploadStatus.next('Get the chunks that need to be uploaded ...')
const { data: _chunksNeedUpload } = await this.uploadApiSvc.getExistChunks(
fileHash,
chunksHash,
)
// 完整的上传参数
this.uploadStatus.next('Building upload params ...')
const paramsMap = new Map<string, FormData>()
chunksBlob.forEach((chunk, index) => {
const data = new FormData()
data.append('files', chunk)
data.set('name', file.name)
data.set('index', index.toString())
data.set('fileHash', fileHash)
data.set('chunkHash', chunksHash[index])
paramsMap.set(chunksHash[index], data)
})
// 获取实际需要上传的分片
const params = _chunksNeedUpload.map((chunkHash) => paramsMap.get(chunkHash)!)
this.uploadStatus.next('Uploading ...')
// 基于实时上传进度的进度
const total = file.size
const currentProgressList: number[] = []
const intervalId = setInterval(() => {
const current = currentProgressList.reduce((acc, cur) => acc + cur, 0)
cb(Math.ceil((current / total) * 100))
}, 150)
await new PromisePool(params.map((param, index) => () =>
this.uploadApiSvc.uploadChunks(param, (current) => {
currentProgressList[index] = current
})
)).exec()
clearInterval(intervalId)
cb(100)
// 获取校验失败的分块并尝试重新上传
this.uploadStatus.next('Verify uploaded chunks ...')
const { data: brokenChunksList } = await this.uploadApiSvc.verifyChunks2(fileHash, chunksHash)
if (brokenChunksList.length !== 0) {
console.log('brokenChunksList: ', brokenChunksList)
return ''
}
// 合并分片
this.uploadStatus.next('Merging chunks ...')
const { data: url } = await this.uploadApiSvc.mergeChunks(fileHash, file.name, fileSize, metadata)
this.uploadStatus.next('Completed.')
return url
}
}
8. 总结
文章参考: 一文吃透👉大文件分片上传、断点续传、秒传⏫ juejin.cn/post/732414…
本文可能有少许不准确或者有误的地方,欢迎评论区赐教。最后,如果觉得还不错,对你有帮助的话,欢迎点赞、收藏、转发 ❤❤❤
原文链接:https://juejin.cn/post/7353106546827624463 作者:困困困困困困