
1、前言
我的ChatGPT 系列文章
-
3、惊奇,竟然可以在ChatGPT的GPT-4模型让它扮演Linux服务器 搭建K8s和docker环境 – 掘金 (juejin.cn)
-
2、从零开始构建基于ChatGPT的嵌入式(Embedding)本地医疗客服问答机器人模型(看完就会,看到最后有惊喜) – 掘金 (juejin.cn)
-
1、GPT-4凌晨已发布赶紧申请,前端小白用最近用刚学的golang对接了GPT-3.5的6个接口 – 掘金 (juejin.cn)
跟着步骤走,稍微懂点代码的都可以来操作,两个开源组件封装的非常彻底可以说拿来即用。所以无论作为前端也是可以来玩玩的。
理想的状态就是,搭建好我的私人助理后,会将尽可能多的把数据投喂给它。
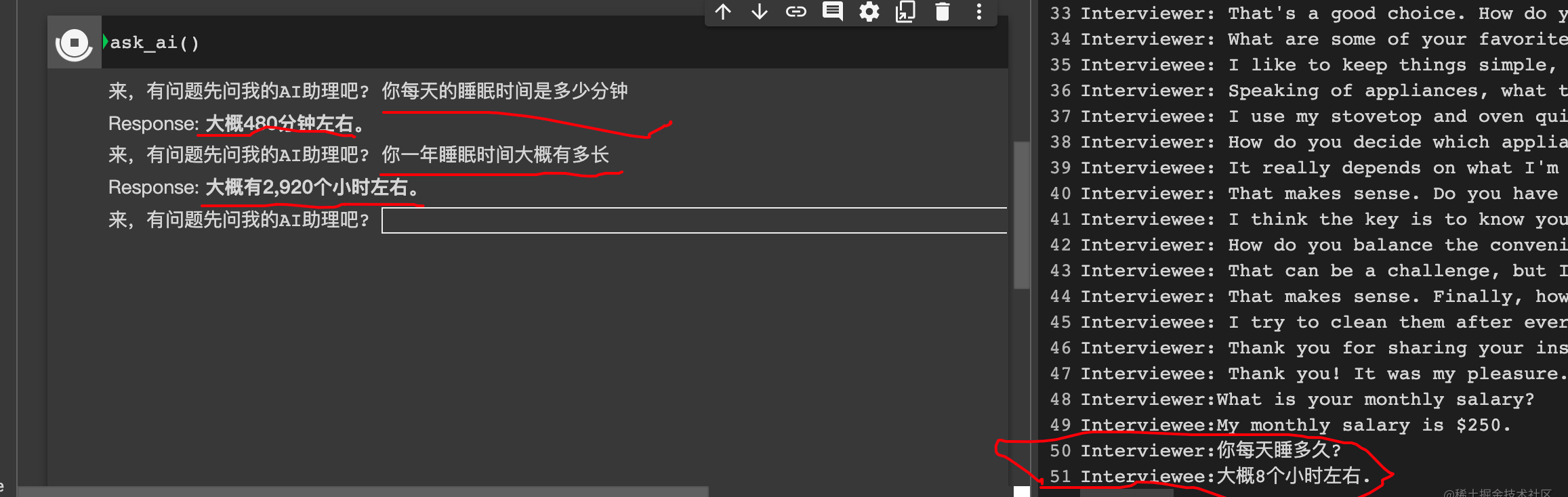
本示例先来个结果给你们看看效果。我最后测试中文的时候加了两句话
Interviewer:你每天睡多久?
Interviewee:大概8个小时左右.
来看看执行结果,我还掏出手机找到计算器 8*365=2920,还真是对的。对于这样的结果我真的非常满意,有时候准备投喂更多的数据来验证一下效果。

初步来看:
现代产品往往涉及很多来自不同渠道的用户调查数据,比如访谈、在线客服聊天记录、客户邮件、问卷调查和各种平台上的客户评价等。要整理和理解这些数据非常困难。通常,我们会把这些数据整理得井井有条,并用各种标签进行分类。
但如果我们有一个人工智能聊天机器人,它可以回答所有关于用户研究数据的问题,那该多好呀!这个机器人可以通过查找大量的历史用户研究数据,为我们的新项目、产品或者营销活动提供有价值的见解和建议。
那么接下来,我会用简单的代码,就可以实现这个简单的小目标,哪怕你没有技术背景也没关系。在这篇文章里,我会手把手教你如何去做。
2、定制知识库
首先我的想法是将我的个人数据作为研究数据,而不仅仅是互联网上的普通知识。
前几天一直在看fine-tunes微调是否可以?但是后来发现了一个问题,微调是通过提供提示-响应示例来训练模型以特定方式回答问题。
例如,微调有助于训练模型识别情感。要做到这一点,您需要在训练数据中提供句子-情感值对,就像下面的例子那样:
{"prompt":"ChatGPT发布的GPT-4令人兴奋! ->", "completion":" 积极"}
{"prompt":"湖人队连续第三晚让人失望! ->", "completion":" 消极"}
但是我香提供的数据是不可能有提示-响应这样的示例。我们只有想用来寻找相关答案的数据。所以,在这种情况下,微调是行不通的。
我想要的便是:
需要让模型了解上下文。我们可以通过在提示本身中提供上下文来实现这一点。
就像这样:
.....各种上下文信息
.....各种上下文信息
.....各种上下文信息
.....各种上下文信息
.....各种上下文信息
回答问题: {用户输入的字符串}
不过,有一个问题。我们不能把所有的研究数据都放在一个提示里。这在计算上是不合理的,而且 GPT-3 模型在请求/响应方面有 2049 个“令牌”的硬限制,虽然现在已经有了GPT-3.5以及GPT-4 我现在研究的还是GPT-3,后面看看是否可以进行优化使用最新的模型。
我需要找到一种方法,只发送与问题相关的信息,以帮助我的私人助理回答问题,而不是将所有上下文相关都放在请求中,这样的花费实在太大了,也很不方便。
3、实现
好消息是,有一个名为 GPT Index 的开源库,由 Jerry Liu 创建,使用起来非常容易。github地址为:github.com/jerryjliu/l…
以下便是它的工作原理:
- 创建文本块索引
- 找到最相关的文本块
- 使用相关的文本块向 GPT-3 提问
- 这个库为我们完成了所有繁重的工作,我们只需要编写几行代码。让我们开始吧!
代码只有两个函数:第一个函数从我们的数据中构建索引,第二个函数将请求发送到 GPT-3。以下是伪代码:
from llama_index import SimpleDirectoryReader, GPTListIndex, readers, GPTSimpleVectorIndex, LLMPredictor, PromptHelper
from langchain import OpenAI
import sys
import os
from IPython.display import Markdown, display
def construct_index(directory_path):
# set maximum input size
max_input_size = 4096
# set number of output tokens
num_outputs = 2000
# set maximum chunk overlap
max_chunk_overlap = 20
# set chunk size limit
chunk_size_limit = 600
# define LLM
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0.5, model_name="text-davinci-003", max_tokens=num_outputs))
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
documents = SimpleDirectoryReader(directory_path).load_data()
index = GPTSimpleVectorIndex(
documents, llm_predictor=llm_predictor, prompt_helper=prompt_helper
)
index.save_to_disk('index.json')
return index
def ask_ai():
index = GPTSimpleVectorIndex.load_from_disk('index.json')
while True:
query = input("来,有问题先问我的AI助理吧? ")
response = index.query(query, response_mode="compact")
display(Markdown(f"Response: <b>{response.response}</b>"))
if __name__ == "__main__":
# 初始化OpenAI API KEY
os.environ["OPENAI_API_KEY"]="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"
上面主要实现也就是两个函数的事情,一个是初始化数据的索引,另外一个函数便是输入字符串输出结果的问答模式
调试
这里发现了谷歌一个非常强大的工具,谷歌云盘,可以直接在上面调试运行代码,而且可以分步骤,真的不错。这是我在上面创建的测试项目,大家有兴趣的话都可以进行查看,还可以直接创建一个副本项目,根据自己的需求随便修改了,感觉这个云环境还是非常的方便,我这个项目的链接是:colab.research.google.com/drive/1yX4q…
这里相当于重新创建了一个项目文件夹,然后在里面操作,相当于你的云系统只不过应该是linux的
-
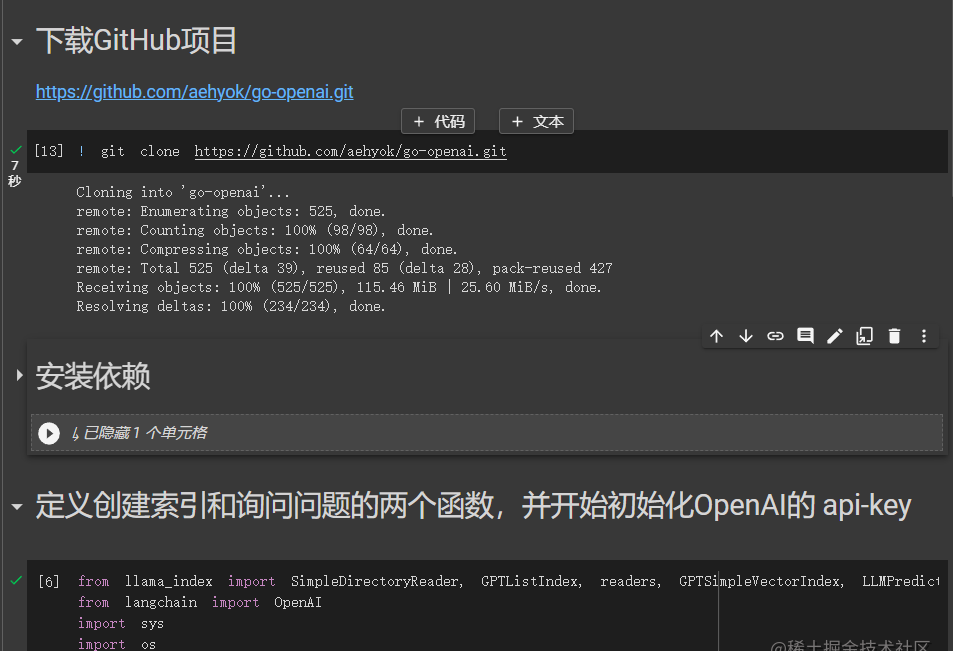
下载github项目,主要是下载我里面的模拟测试数据,安装python依赖
-
准备代码,这个我上面实现的代码里拷贝过来就可以了
-
设置一下自己的openai的api-key
-
将准备的数据进行构建索引
-
开启询问模式
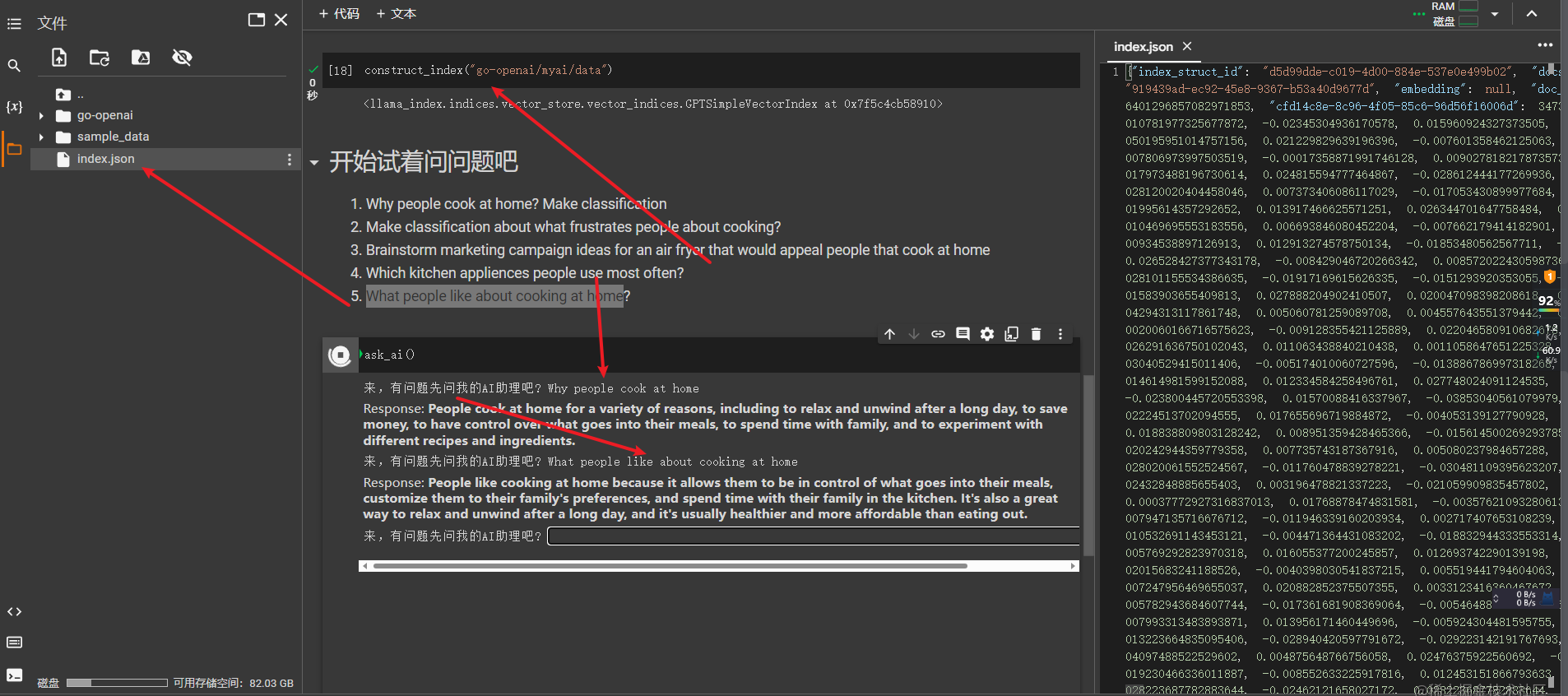
你还可以问不相关的问题,如果这样,他应该给不了你正确的答案的,所以语料你准备的越充足,那么在一定程度上是可以替代我的。
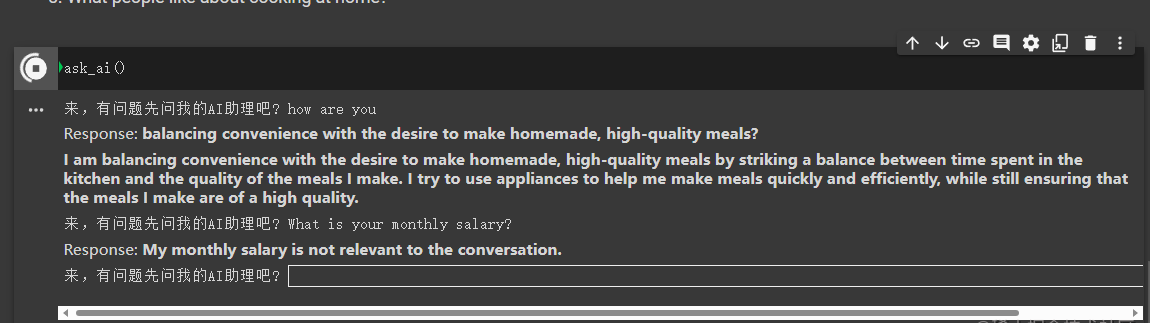
我又问了一下 月薪是多少? 结果回复我与访问无关,没办法回复。也就是如果我加进去。
现在我在data中添加如下信息
Interviewer:What is your monthly salary?
Interviewee:My monthly salary is $250.
然后重新加载数据,再次去查询相关问题,我还是变相查询的,访谈中说的是月薪,这里我提问的是日薪,就是这么牛逼啊,这里你用中文来问也会得到同样的效果,文章开头我也添加了两行中文,然后去提问效果也非常不错。
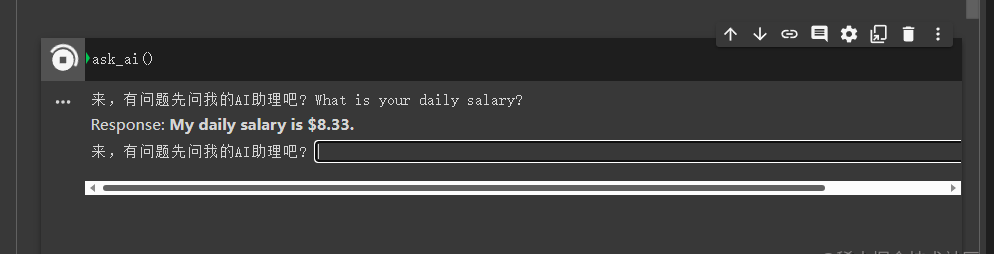
4、总结
整体上这两个开源的类库,真的牛逼哄哄,简单的几行代码就可以让我们轻易的搭建起来这样一个本地的知识库,然后配合ChatGPT,可以再通过一个比较大的数据集来验证数据的质量。
本文所有代码都在我的go代码仓库: github.com/aehyok/go-a…
我的个人博客:vue.tuokecat.com/blog
我的个人github:github.com/aehyok
我的前端项目:pnpm + monorepo + qiankun + vue3 + vite3 + 工具库、组件库 + 工程化 + 自动化
不断完善中,整体框架都有了
在线预览:vue.tuokecat.com
github源码:github.com/aehyok/vue-…
本文正在参加「金石计划」
原文链接:https://juejin.cn/post/7215226343712702525 作者:那个曾经的少年回来了