
前言
人类历史中,文字是最伟大的发明之一,它帮助渺小的人类,跨越时间的长河,记录漫长的岁月,人类文明通过文字得以不断传承、发展和进步。
现代的发展,人们发明了计算机,那么在计算机的世界里,文字又是如何存储与传递的呢。
乱码问题
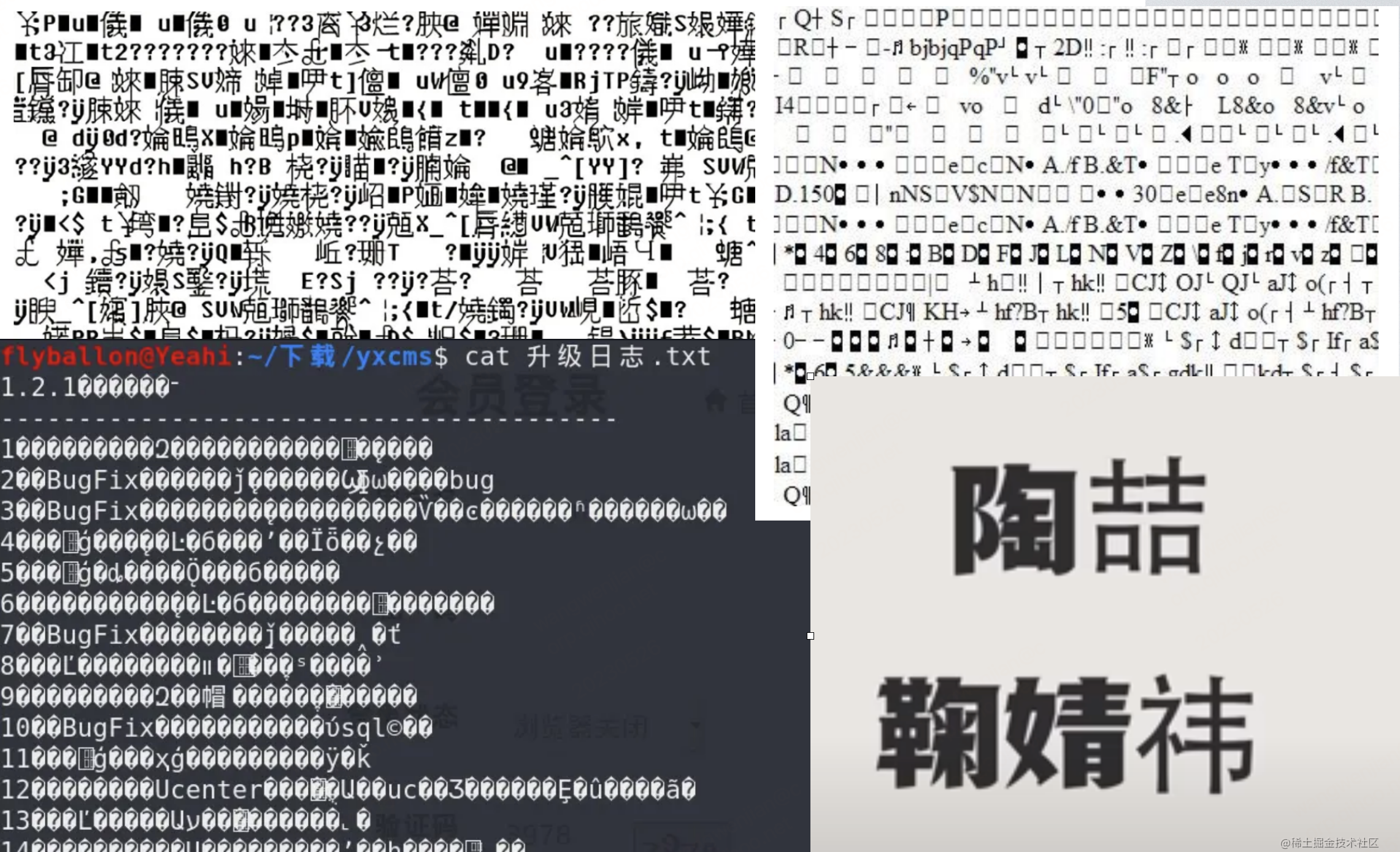
理解概念,我们先从日常的问题入手,看到下图有些人可能会觉得比较眼熟,因为在过去的很长一段时间里,在我们工作和生活中使用电脑时经常遇到关于文本乱码的问题,比如非常有名的【锟斤拷锟斤拷锟斤拷】乱码,或者是看不懂的古文、是一堆没有意义的问号、是一堆小方块,或者是一些虽然能正常显示,但总和周围的文字显得格格不入生僻字。
虽然现在随着硬件的发展和规范的制定,我们已经很少能看到乱码问题,但我们仍然能从此入手,去了解下计算机是如何将字符渲染到我们的眼前。

字符、字符集与字符编码
在了解之前,我们应该先清楚三个最基本的概念,字符、字符集、字符编码,后面所有的内容都将围绕着这几个基本概念展开

字符
-
字符是一种抽象的概念,可以是一个字母、数字、标点符号、汉字,一个表情、一个图像或者你随手写画的任何图案。
-
在过去,字符可能被刻在石头上、甲壳上、竹简上、宣纸上,抽象的字符背后代表着人们具象的理解。
-
而在计算机中,显然不能将一个字符直接拿去存储,计算机的底层只能存储二进制,我们需要将字符转化为二进制存储到计算机中。
字符集
-
而一堆字符的集合,就叫做字符集,比如说,如果有中文字符集,那就是由一堆汉字组成的,而英文字符集,就是由一堆英文字母组成的。
-
字符集就像是一个密码本,存储着字符与某种规律集合的映射,比如二战中常用的电台,发送的摩斯密码就通过“长短点按”的方式传递信息,收到“长短点按”信息后再通过密码本将点按翻译成正常文字
字符编码
人类世界有大量的字符,为了让计算机认识这些字符,我们需要把字符转换成计算机能识别的二进制,再用二进制对照着字符集将字符渲染到屏幕,这个将字符转为计算机能识别的二进制规则,就叫做“字符编码”
编码方法
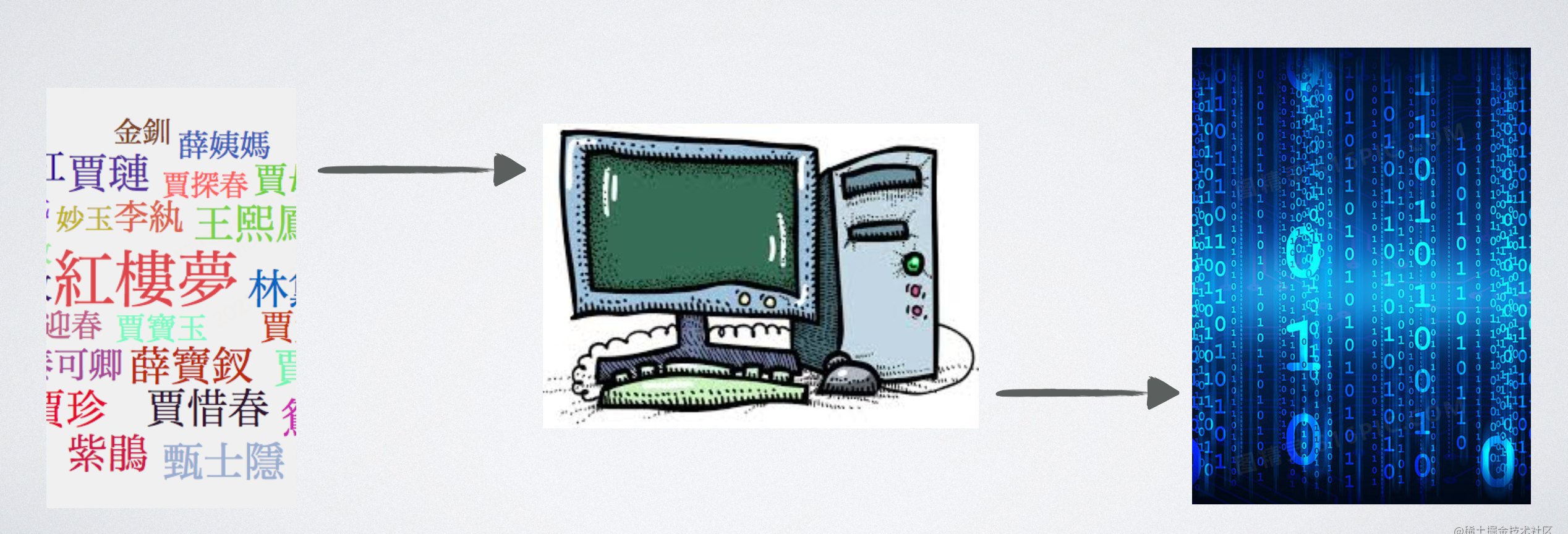
现实世界有这么多种类的字符和字符集,但是计算机一个也不认识,计算机只能存储二进制数,那我们怎么将现实中的字符,编码进计算机中呢?
1. 字符集编号
-
首先我们选定一批要编码的字符(比如英文26个大小写字母),然后我们将这批字符排成一个有顺序的集合(就是字符集),此时从0开始字符集中每一个字符都会有一个的唯一编号,我们再将这个编号转化成二进制存入计算机中。
-
在计算机中编号和在屏幕上要渲染出的视觉效果形成映射,计算机就可以通过二进制将字符存储下来了,在不同的设备之间也能通过二进制作为数据的传输,只要他们有相同的字符集,编码方式和硬件渲染的效果
2. 编码过程
- 计算机需要以0 1二进制存储
- 计算机存储的基本单位是字节,1字节=8位二进制,每一位二进制可能是0或1,那么8个二进制就有2^8种情况,也就是256种状态,那么一个字节最多就能映射256种字符。
- 我们将前面排好的字符集和1个字节的256种二进制映射起来,我们就可以通过二进制找到字符了,将二进制存入计算机中,我们就将字符成功的存入计算机中了。
比如一个字符A可能在一个字符集中排序65位,转为二进制就是1000001,我们就将1000001存到计算机中了 
ASCLL字符集
这个时候你可能要说了,1个字节只能存256种字符,这怎么能够用呢。
实际上,现实世界中第一个字符集就是采用这种方式编码 ,那就是大名鼎鼎的ASCLL。
那为什么他能用呢,因为美国的字符就只有拉丁字母大小写,阿拉伯数字,再加上一些符号和键盘的一些控制字符,满打满算加起来就只有128个字符,1个字节256个码位,他用一半还剩了一半,所以非常够用。

到此为止我们举例讲了一个完整的方法,将字符转为二进制数存入计算机中,看起来并不复杂。
可是真的这么简单吗,为什么还会有字符乱码产生呢?
世界上不止一种语言…
因为世界上不止一种语言,世界上的文化是开放而多元,就像我们无法用一套文字去统一整个人类文明
字符集的乱纪元
欧洲国字符集扩充
- 欧洲很多国家也同美国类似使用拉丁字母这一套作为语言,但还是会有很多差别,为了适应本国情况,欧洲国家将ASCLL剩余的128个空位进行了扩充,在此中间诞生了很多从ASCLL衍生出的字符集,众多字符集互不兼容,这就导致同样的文件同样的计算机在不同国家打开显示就会不同。
亚洲国家字符集
-
到了亚洲,就更加复杂了,亚洲国家的语言文字非常复杂,比如中文,日文,韩文,泰文,越南文,藏文,蒙文,维吾尔文等等,这些语言文字的字符集都是非常庞大的,而且完全不同的。
-
比如中国发布的GB2312常用简体字字符集,就包含了6000多个字符,而1个字节只能存储256种字符,是远远不够的,这就导致了新的字符集与新的字符编码方式产生,一个字符可能需要1个字节,2个字节,甚至3个字节来存储,而计算机无法自动识别二进制该用那种方式读取,这就导致了同样的文件,同样的计算机在不同国家打开,会出现完全错乱的情况,也就是我们常看到的乱码。
问题严峻
随着计算机使用越来越广泛,问题更加突出,虽然中国最早制定了GB2312,但只包含了6000多个常用简体字符,很多生僻字不在其中,这就导致很多生僻字根本无法在计算机中打出来:
- 比如陕西biangbiang面的biang到现在也无法打出来。
- 如果你的名字中有生僻字,在公安局无法办理身份证,你就必须要改名甚至改姓
- 有些文字能出现在计算机中也看起来也格格不入,因为设计好的字体可能只设计了GB2312常用简体字样式,生僻字没有在字体库中,那只能系统展示默认字体甚至无法展示

Unicode大一统
天下大事,合久必分,分久必合
混乱的终点即是统一,当时世界急需一个大一统的字符集,统一全世界的字符,所以Unicode应运而生
Unicode
-
Unicode字符集被分成17个平面,每个平面 65536 个码位,共可容纳110 万个字符,使其能够以单一的通用标准支持世界上所有的语言和文字。
-
随着时间的推移Unicode不断扩充,最近一次更新在2022年9月13日发布了15.0版本,目前共包含149,186个字符。
-
Unicode 已经成为现代所有操作系统、计算环境、编程语言和应用程序的字符编码的标准。
Unicode的字符编码
与之前所有字符集不同,过去的字符集一般比较小并有与之对应的字符编码方式,比如ASCLL 1个字节,GB2312 2个字节,之前字符集和字符编码也是不分家的,在window上经常看到直接以字符集命名的字符编码,如:ASCLL GBK
但是Unicode是个超大的字符集,实现过程有过多种编码方式,不同的编码方式无法互通:
UTF-32
UTF32最为简单粗暴,和ASSLL一样采用定长字节的方式编码,每个字符固定使用4个字节,与Unicode完全兼容,但是现在人类最常用的字符基本都在Unicode的第一平面,用1个字节就可以表示,这样就造成了大量的浪费,所以现在基本弃用。
UTF-32
UTF16采用2字节和4字节变长的方式编码,JavaScript采用方式与此类似,但是他固定使用2/4字节存储很多时候同样会造成浪费,目前是比较常用的编码方式。
UTF-8
UTF8采用1-4字节灵活变长的方式存储,将空间利用到极致,毫不浪费,是现在Unicode最主流的编码方式,操作过程也更加复杂,如下图所示

UTF-8将每个字节的前几个二进制位作为功能区:
- 对于1字节能表示的字符,字节的第一位设为
0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。 - 对于
n个字节才能表示的字符,第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode码。
所以采用UTF-32中编码后的的二进制与Unicode码是一致的,都是直接转换,而UTF-8因为借用了二进制前几位作为功能位,导致只有1个字节能表示的字符转换后的二进制才与Unicode码相同,其他都是有差别。
结尾
总结下我们常见的乱码问题,通常就如上文所说,在字符集与字符编码未统一的年代,计算机很难有一个最准确的方法得知,此时的二进制文本是需要以什么编码方式打开的,比如我用GBK编码方式写的文本发给你,你的电脑默认用UTF-8打开自然就会出现乱码,比如一堆问号或乱七八糟的文字
而我们常见的锟斤拷锟斤拷乱码就是因为用GBK编码的文本,被UTF编码打开就是一堆问号,一堆问号被UTF转存后,再通过GBK编码打开,就是我们熟悉的锟斤拷了。
参考文献
原文链接:https://juejin.cn/post/7238439667137511483 作者:阿祖zu